Hi TI
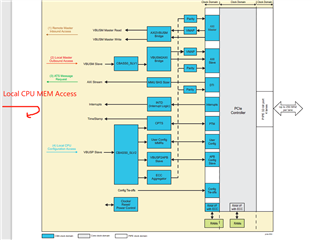
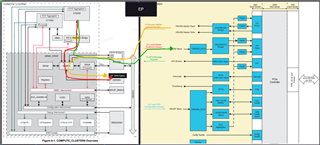
Problem Description: I've encountered a performance issue regarding data transfer while developing with a PCI Express (PCIe) device. Specifically, I've observed that the speed of data transfers using Direct Memory Access (DMA) and CPU access (via memcpy_toio and copy_from_iter interfaces) to the Base Address Register (BAR) space of a PCIe Endpoint (EP) device is similar at the 64KB data size level, and significantly slower than accessing memory allocated through kmalloc or dma_alloc_coherent.
Attempted Solutions and Observations:
-
DMA vs. CPU Access: I tried accessing the PCIe device's BAR space using both DMA and CPU methods and found that their transfer speeds do not significantly differ at the 64KB data size level.
-
Memory Allocation Method: I changed the memory allocation method for the PCIe BAR space from
dma_alloc_coherenttokzalloc, hoping to observe performance changes based on the memory allocation strategy. However, this modification did not improve access speed, which remained much slower than accessing memory allocated throughkmallocordma_alloc_coherent. -
Synchronization Mechanism Impact Exclusion: To ensure that performance issues were not introduced by synchronization overhead, I implemented a producer-consumer model based on flag bits to control access to the BAR space. The results indicated that the access speed remains slow even when direct resource competition is avoided.
Questions:
- I would like to understand why, even in the absence of direct resource competition, the speed of accessing the PCIe BAR space directly via DMA or CPU remains significantly lower than accessing standard memory.
- Could the PCIe bus bandwidth or latency, hardware features, or driver implementation methods be causing this performance behavior? If so, are there recommended optimization strategies or configuration adjustments to improve this situation?
- What could be the reason for the similar speeds of DMA and CPU access at the 64KB data size level? Does this imply that the fixed overhead of data transfer dominates at this data size level?
Expected Answers:
I am looking for detailed explanations about the reasons behind the observed performance behavior, along with possible optimization suggestions or solutions. Specifically, I am interested in learning if there are best practices for specific PCIe hardware and configurations that could enhance the data transfer efficiency of PCIe device BAR spaces.