


Hello,
We are trying to develop a kernel that works on C7 DSP using streaming engine, for reduced memory complexity we want to use MSMC 1, extended memory which as 3MB capability.
The idea is to move the images in DDR to MSMC and back from MSMC to DDR using streaming engine. Could you provide us any sample examples that could help us achieve this task. We looked at C7 Training material that has information on how to use streaming engine, but that does not mention anything about streaming the data back to DDR memory.

As mentioned in the image above, SE cannot be used to write instructions but to input instructions. what does this exactly mean in terms of data streaming, please elaborate.
Here is the MSMC we want to invoke for the kernel:
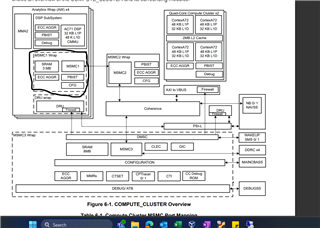
Thank you.

