Other Parts Discussed in Thread: SYSCONFIG
Hi TI Experts,
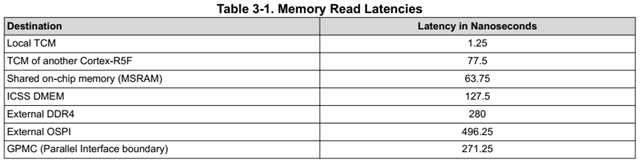
Customer is trying to put a small application run by R5f in the 2MB SRAM shown below.

We think the execution speed is the same as the corresponding clock for the SRAM.
Could you help to check if this speed is the same as R5f 800Mhz, or it will reduce to 400MHz or any other values?

Thanks a lot!
Kevin