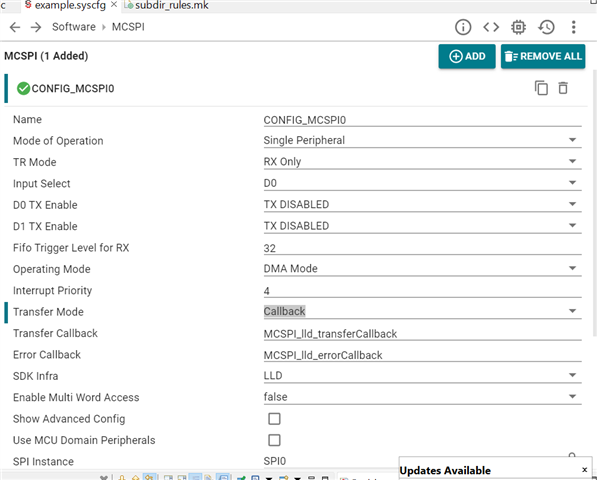
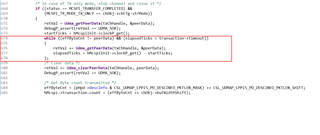
Other Parts Discussed in Thread: SYSCONFIG
Hello,
We have the following system architecture:

We are using the ADC as an SPI master and we would like to use McSPI1 and McSPI3 as slave controllers, that in an R5F0 application. The idea is to configure the UDMA in a way, that we basically implement endless circular reading, i.e.
- The ADC is configured for delivering 32-bit data frame, using 2 DPORTS (Ch0-3 on D0, CH4-7 on D1). The sample rate is configured to 128 KSPS, which results in 32,7 MHz data clock
- The DMA is provided with a buffer in MSRAM, which is 16KB (for example)
- The DMA is configured in a way, that it delivers an interrupt for each 32 packets read (32xFSYNC), altogether 512 bytes (4ch x 4 bytes x 32 frames)
- After delivering the interrupt, the DMA continues with the next 32 packets and the target offset in the memory is incremented with 512 bytes
- The process continues, until the buffer end is reached, then the DMA should start from the initial buffer offset
This was trivially achievable with other controllers (ST), using either DMA in circular mode and 1/4 Full, 1/2 Full and Full interrupts, or Double-buffering. With other SoCs (Xilinx) that was achievable trough programming the scatter-gather DMA structures and descriptors.
The problem we see with Ti, is that there is no practical guide how to use the UDMA, or at least we were not able to find one. The examples that could eventually help and that are provided with the MCU+ SDK, are using BCDMA, which I am not sure if it works in our case.
Any advice will be highly appreciated.
Thanks!