Tool/software:
Hi Team,
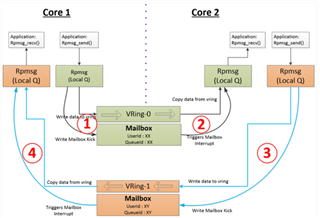
In the related thread, it says that access to DDR from M4F core takes significantly longer. My customer is considering using IPC RPMsg. It says that shared memory can be either DDR or internal memory. Does this mean that when they use IPC RPMsg to load data from DDR, it will take significantly longer as well? Is there some workaround for this?
Also, when it refers to shared internal memory, is it referencing the 64KB OCRAM?
Best regards,
Mari Tsunoda