Other Parts Discussed in Thread: TDA4VM
Tool/software:
HI, TI experts:
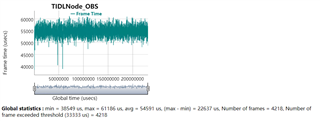
We used the same model, configuration, and program to run on TDA4VM (SDK8.0) and TDA4VE (SDK9.2) respectively (both TDA4VM and TDA4VE have 2G DDR), and found that the time spent on TDA4VE was nearly 20ms more than on TDA4VM. However, from the perspective of configuration, TDA4VE has an improvement in MMA compared to TDA4VM. But the actual test results are opposite, please help confirm the reason. Thankful.
here is the result of TDA4VM(SDK8.0)
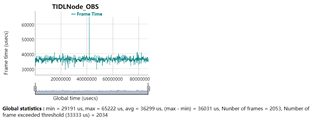
here is the result of TDA4VE(SDK9.2)