


Part Number: PROCESSOR-SDK-AM68A
Tool/software:
Hi,
While progressing with QATv2, there are two issues:
(1) init() function within QATv2 needs to have add_methods=True, but it is implemented with a False value, which is causing problems. (first image)
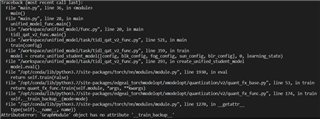
(2) After forcibly modifying the TI code to True, a second error occurred. This part involves the detailed implementation of layer QAT, which is difficult for us to handle, so we have not been able to proceed. (second image)
First image:

Second image:
Thank you,
Youngheon
