


Tool/software:
Hi TI team,
We are working on deploying yolov8m to the TDA4VM. We are using Processor SDK J721 9.2.
Can you please check our steps, our understanding of the edgeai-tensorlab and advise how to proceed?
In the scope of edgeai-tensorlab, we are using the following:
0. Inputs:
- Model is yolov8m onnx (default model from ultralytics converted to onnx, opset 11).
- For the prototxt file we used attached file – yolov8m_onnx.prototxt (manually generated, based on the yolov8s prototxt from the online model)
1. edgeai-benchmark :When we set tidl_offload to false, it seems that everything is fine and we receive the result shown in the attached log – offload_false.log.
2. edgeai-benchmark : Setting tidl-offload to true
- Verifying that environment is OK: We successfully ran YOLOv8s lite with the existing configuration in the detection_v2.py file (we found the attached model from previous discussions on the forum (link). Model is also deployed to the board successfully.
- YOLOv8m:
1. We tried to compile our YOLOv8m model from Ultralytics, converted into ONNX following yolov8s example. We used the same configuration and prototxt (with only the necessary changes based on our model graph, name of output node) because both of them trained on the COCO dataset.
2. With our current setup, we receive the error shown in the yolov8m.log.
3. Do you see some issues with this approach? Do you have some suggestions on how to create the appropriate prototxt file automatically?
4. We noticed that to overcome issues related to the unsupported layers of YOLOv8m, we have to perform a "surgery" on the model in the model optimizer. We are proceeding now with this step to adapt our model for the benchmark. Our expectation is that this would give us model for the edgeai_benchmark, which would then be able to generate the necessary files for the model deployment on board. Correct?
5. For the surgery we are using default function for replacement.
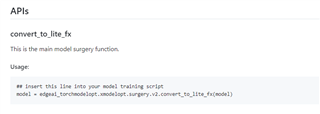
6. Considering that the surgery functions also perform model training with 100 epochs, which requires a considerable amount of time, we would like to know what are the ways we could shorten or omit that training process, in order to first perform model verification, and will train properly afterwards?
Thanks in advance.





