Other Parts Discussed in Thread: TMDS64EVM
Tool/software:
Hi,
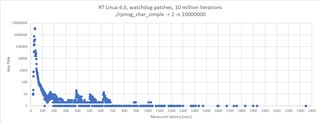
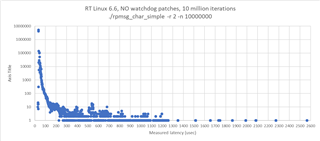
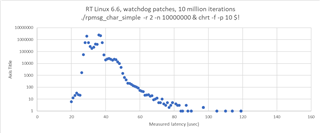
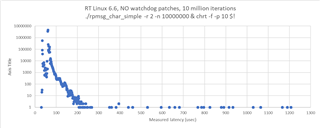
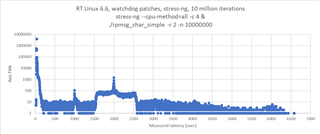
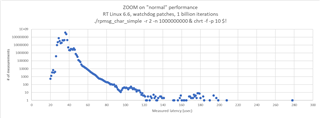
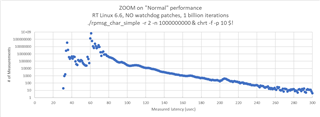
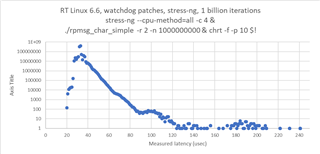
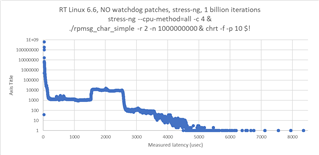
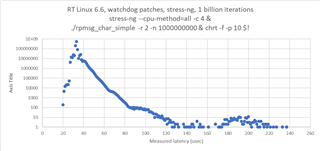
i measured the communication performance with RPmsg between a UserSpace Task on A53 and the R5 running FreeRTOS. The amount of data was 4KB. I have some outliners with 2-3 milliseconds. Could you please provide some performance updates.
cyclictest looking good with 60us.
Right now i'm using:
SDK 09_02_01_10 with Kernel 6.1 on the SK-AM64B.
and
https://git.ti.com/cgit/rpmsg/rpmsg_char_zerocopy/
I tried to change the example to TCM only for the 4K data. No improvements there.
Thanks a lot