


Tool/software:
Hi,
i have a question related to RPmsg on the AM64. To get the best performance i tried to change the rpmsg_char_zeroccopy example to use TCM. The changed example is running fine. The data is inverted on the Cortex-R5 an validated in UserSpace Task on Cortex-A53.
The example uses shared memory and RPmsg just to signal the available data.
Is it enough to change the data that will be exchanged between the cores to TCM?
The other thing that I do not understand:
If I look into TRM memory map main domain, I can see TCM B for Cortex-R5 Core 0
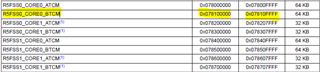
So I changed shared mem in device tree to the TCM address.
apps-shared-memory {
compatible = "dma-heap-carveout";
reg = <0x00 0x78100000 0x00 0x2000>;
no-map;
};
If I print the address on the R5 with ibuf.addr it is the right address. If read out the data with devmem2 on A53 I see the inverted data. All looks good!
But if I look into memory map file for R5 Core 0:
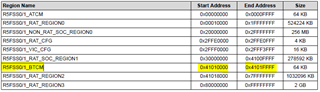
The address for TCM B is another address then in ibuf.addr.
Could you please tell me how this could be?
right now i''m using:
SDK 09_02_01_10
thanks again!
