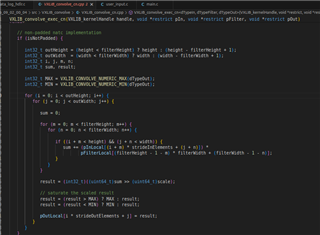
Tool/software:
Hello,
SDK version: 9.2.0.5.
We are currently trying to build a custom kernel that utilizes convolve_row API from MMALIB. To support our development, we started looking at sample example code provided at
mmalib_09_02_00_08/ti/mmalib/src/cnn_c7xmma/MMALIB_CNN_convolve_row_ixX_ixX_oxX
As part of it we have a few queries listed below to which we might need your support:
1. Could you please give us a brief explanation of what exactly are the parameters considered for this testing? I ask this because when I see the test_data I found very large kernel and test_feature map arrays. But in the MMALIB_CNN_convolve_row_ixX_ixX_oxX_idat.c I see the values of kernel width and kernel height are 3 (this was confusing because the regIn and refKernel matrices when observed are very large) furthermore the refIn matrices for all the test cases seem to contain only 0's and no other numbers. Please kindly help us understand what exactly is tested in this sample code.
2. In the sample test code: MMALIB_CNN_convolve_row_ixX_ixX_oxX_d.c, predicate registers are created only if the stridewidth and strideheight are 1. However, in our case, we are planning to have a stride of 4 on both the directions. Should we implement predicate registers as well?
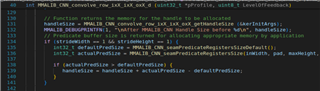
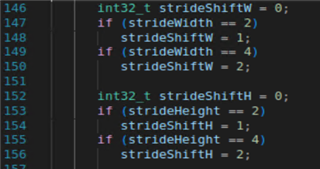
3. within MMALIB_CNN_convolve_row_ixX_ixX_oxX_d.c, the values of strideshift are less than stridewidth and stride height, please explain the significance of this change and what should this be in our case:
4. What exactly should be the value of ValidColsIn, ValidRowsIn, inChOffset, subN, ValidColsPerRowIn, outputPitchPerRow, InputPitchPerRow,: please elaborate their explanation within the documentation is not clear enough and is confusing.
5. Please provide some more explanation on how the following equations were derived:
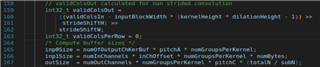
Kindly provide your responses for each question.