

Hi,
I would like to ask a question on McASP.
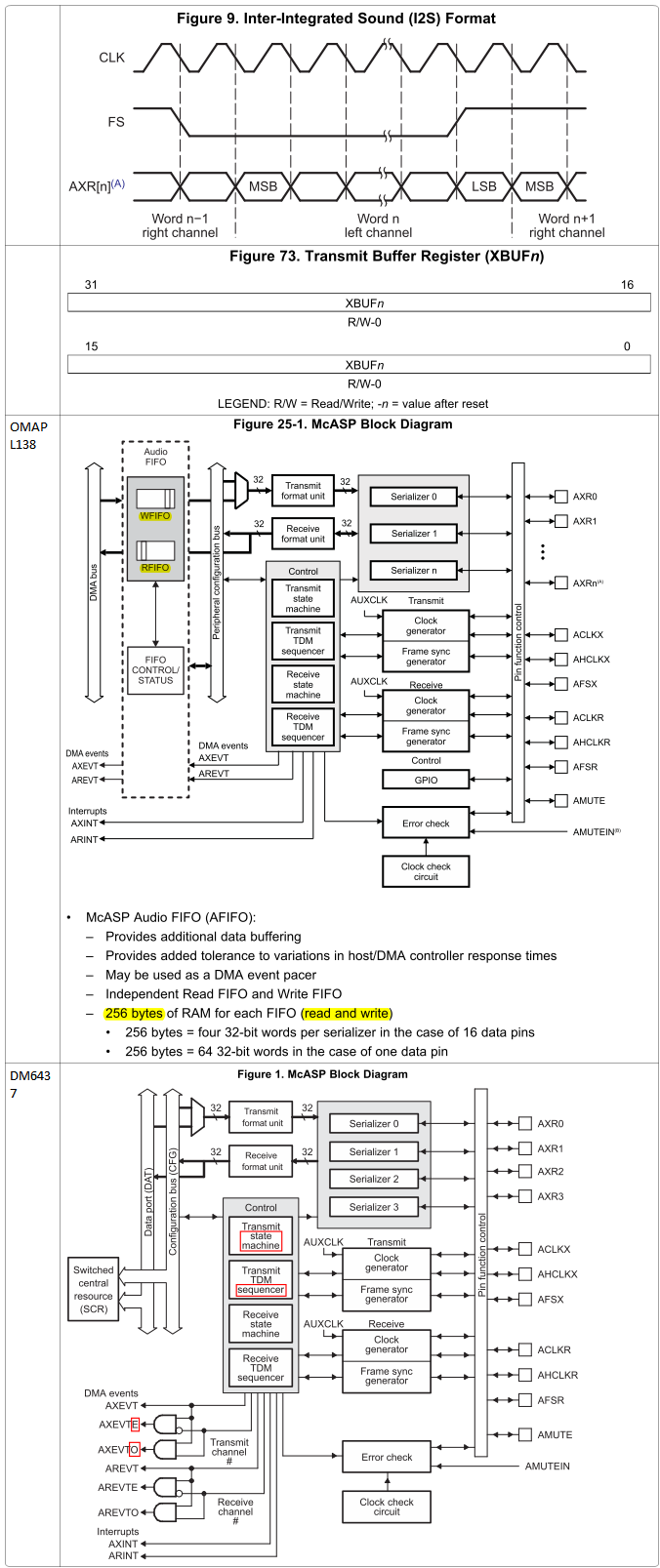
A problem I noticed on McASP peripheral is its extremely small buffer size. On both OMAPL138 and DM6437, there is only one 32-bit buffer for each serializer, and some easy calculation show the amount of CPU/DMA services for a typical CD-quality audio. On OMAPL138, I noticed the addition of 256-byte write and read FIFO buffer, which significantly reduced the number of services per second. Despite this reduction, some 600 services per minute is still significant.
The biggest problem is on DMA. The relationship between DMA's service time and data amount is linear but with a constant positive offset on the ordinate as shown in Question on AM1808 EDMA3. The 26ms number given in that post was not accurate as later discovered, and the actual constant time could be as low as 2ms; however, even for OMAPL138 which has 256-byte McASP FIFO, this still means there requires over 600 DMA transfers per second, each time transferring merely 4 bytes of data. Several issues exist for this operation:
1. If each DMA transfer takes at least 2ms of time, can this 600+ transfers be completed in 1 second?
2. 600+ DMA transfer means requesting SCR bus (switched central resources) bus 600+ times per second. Could SCR respond promptly enough? If there are other uses of DMA, would interference cause delay in DMA's servicing McASP, and subsequently degrading of the sound quality (most noticeably, lowering of pitch as perceived by the ear)?
3. It is clearly again the general principle of DMA operation, which is aimed to transfer larger amount of data between memory locations. The 4-byte (256-byte if FIFO used) amount per transfer is inappropriate for DMA. Why it is designed like this?
4. For DM6437 whose McASP is without FIFO, the 44100 times of servicing per second, either from CPU or DMA, is hardly imaginable. And if by DMA, I fundamentally doubt if DMA could respond fast enough to catch up with that frequency.
|
|
CD Audio |
|
Sampling frequency |
44.1 KHz |
|
Bit depth |
16 |
|
Channel |
2 |
|
Data rate |
44.1K × 16 × 2 = 44.1k × (32bit = 1 word) = 44.1k word(s) |
|
XBUF size |
32 bits = 1 word |
|
FIFO @ OMAP L138 |
256 bytes = 64 words CPU/DMA transfer: 44.1K÷64 = 689.0625/sec |
|
FIFO @ DM6437 |
N/A CPU/DMA transfer: 44100/sec |
As a comparison:
http://computer.howstuffworks.com/sound-card3.htm said:As with a graphics card, a sound card can use its own memory to provide faster data processing.
A sound card is provided on PC at additional cost, which might not be justified for a single-integrated embedded processor. However, even if McASP cannot have its own internal memory, it might still be designed to have the ability to "fetch" data from memory, as opposed to being "fed". A more ideal design as I simply wished would be allowing an amount of sound data, say 5 seconds, to be placed linearly at a memory location, and McASP would fetch data equaling XBUF size each time, and increment address pointer automatically; upon finishing of transmission of the last XBUF to serializer, it fetches another word of data as pointed by the incremented address pointer, and in this mode everything can be done automatically without the intervention of CPU/DMA.
Why it is not designed like this?
Could anyone advise me of the proper mode of McASP servicing? How much CPU time it typically occupies? And if there are both Video and Audio stream, possible plus other job at the same time, how should CPU time be properly allocated for different streams?
Zheng
