Tool/software:
Hi,
[Question]
Has TI sdk encountered any time-out issues with VPAC(TIVX_TARGET_VPAC_MSC1) before, and what's the reason and any solutions?
[background]
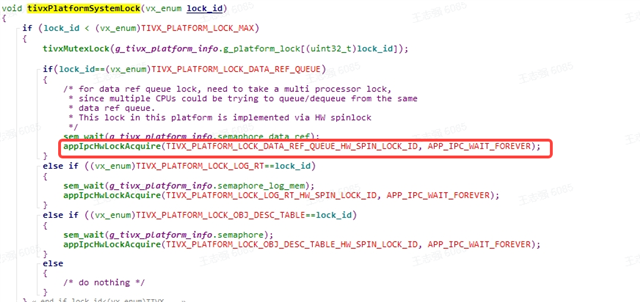
Here is an issue that ADAS function(NOA) had exit by accident, reported by the customer.
According to log analysis, the image processing model of scaler had timed out, detail:
After A72 sent an image processing command(to adjusting front-camera image size for TIDL model) to VPAC (TIVX_TARGET_VPAC_MSC1), VPAC did not return the result within 150ms, but delayed about 250ms
After a few minutes, another time-out occurred... and it had happened multiple times within an hour then never happened.
By our design, When time-out occurs, the perception module will report a failure and the ADAS function has to exit.
At present, it cannot be reproduced as VPAC always responded in a short time(<50ms), but we are not sure whether it will happen again since a large number of vehicle released in the market.
Ti sdk version is 8.2.
task load: ( was from the car of customer, the statistics data output per 30 seconds, here just provide one segment for example)
----------------
HWA performance statistics,
===========================
HWA: VISS: LOAD = 53.19 % ( 311 MP/s )
HWA: LDC : LOAD = 41.58 % ( 161 MP/s )
HWA: MSC0: LOAD = 52.98 % ( 232 MP/s )
HWA: MSC1: LOAD = 14.81 % ( 12 MP/s )
HWA: DOF : LOAD = 11.79 % ( 12 MP/s )
DDR performance statistics,
===========================
DDR: READ BW: AVG = 4519 MB/s, PEAK = 11811 MB/s
DDR: WRITE BW: AVG = 2895 MB/s, PEAK = 9062 MB/s
DDR: TOTAL BW: AVG = 7414 MB/s, PEAK = 20873 MB/s
Detailed CPU performance/memory statistics,
===========================================
PERF STATS: ERROR: Invalid command (cmd = 00000003, prm_size = 388 B
CPU: mcu2_0: TASK: IPC_RX: 1.53 %
CPU: mcu2_0: TASK: REMOTE_SRV: 2.82 %
CPU: mcu2_0: TASK: LOAD_TEST: 0. 0 %
CPU: mcu2_0: TASK: TIVX_CPU_0: 7.34 %
CPU: mcu2_0: TASK: TIVX_NF: 0. 0 %
CPU: mcu2_0: TASK: TIVX_LDC1: 5.88 %
CPU: mcu2_0: TASK: TIVX_MSC1: 8.45 %
CPU: mcu2_0: TASK: TIVX_MSC2: 5. 7 %
CPU: mcu2_0: TASK: TIVX_VISS1: 18.94 %
CPU: mcu2_0: TASK: TIVX_CAPT1: 1.29 %
CPU: mcu2_0: TASK: TIVX_CAPT2: 1.41 %
CPU: mcu2_0: TASK: TIVX_DISP1: 0. 0 %
CPU: mcu2_0: TASK: TIVX_DISP2: 0. 0 %
CPU: mcu2_0: TASK: TIVX_CAPT3: 0. 0 %
CPU: mcu2_0: TASK: TIVX_CAPT4: 0. 0 %
CPU: mcu2_0: TASK: TIVX_CAPT5: 0. 0 %
CPU: mcu2_0: TASK: TIVX_CAPT6: 0. 0 %
CPU: mcu2_0: TASK: TIVX_CAPT7: 0. 0 %
CPU: mcu2_0: TASK: TIVX_CAPT8: 0. 0 %
CPU: mcu2_0: TASK: TIVX_DISP_M: 0. 0 %
CPU: mcu2_0: TASK: TIVX_DISP_M: 0. 0 %
CPU: mcu2_0: TASK: TIVX_DISP_M: 0. 0 %
CPU: mcu2_0: TASK: TIVX_DISP_M: 0. 0 %
CPU: mcu2_0: TASK: IPC_TEST_RX: 0. 0 %
CPU: mcu2_0: HEAP: DDR_SHARED_MEM: size = 16777216 B, free = 14971904 B ( 89 % unused)
CPU: mcu2_0: HEAP: L3_MEM: size = 262144 B, free = 178688 B ( 68 % unused)
--------------