Part Number: TDA4VH-Q1
Other Parts Discussed in Thread: TDA4VH
Tool/software:
Hi,
We are encountering data corruption when running inference on the TDA4VH.
The observations we encountered so far:
1. Affects openvx allocated memory.
2. Corruption can be observed on the same buffer locations.
3. One of the buffers that gets corrupted is an output buffer that is filled by a node that runs on the VPAC's LDC (tivxVpacLdcNode).
4. The buffer corruption happens only after an inference of some DNNs.
For the inference and TIDL control we are using onnx_runtime library (libonnxruntime.so.1.14.0+10000005).
We are using SDK 9.2 along with the following updates:
1. mmalib_10_00_00_09
2. pdk_j784s4_09_02_00_30
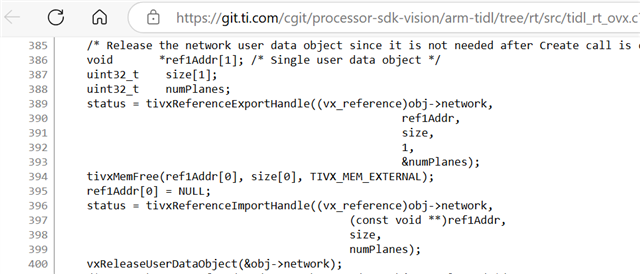
Attached is an exported image affected by the memory corruption.