



Tool/software:
I feel that I did not phrase my previous question clearly, so I would like to ask it again more precisely.
My environment consists of QNX 7.0 and TI SDK 7.0, where applications operate independently as separate processes.
From my understanding, when two applications run in parallel, each host pointer maintains its own virtual memory address.
In this context, if 'host to shared' function is called under a race condition, could memory fragmentation occur?
For instance, suppose App1 utilizes NV12 (Y, UV) while App2 uses RGBA. Additionally, assume that both applications create an image buffer at approximately the same time.
Is it possible that App1's Y component is allocated to physical memory first, and before the UV component is assigned, RGBA is allocated to physical memory? This could result in the end address of the Y buffer and the start address of the UV buffer being non-contiguous.
To allocate NV12 images for QNX’s screen API, I require NV12 in a memory state that ensures contiguous allocation.
However, when multiple images are allocated under race conditions, I have observed frequent memory address fragmentation in the shared pointer.
I have attached a table summarizing my findings.
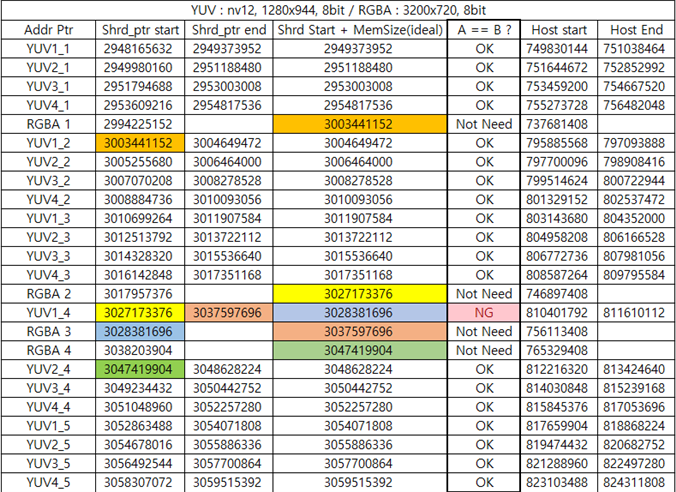
(A table is attached for easy analysis.)
| YUV : nv12, 1280x944, 8bit / RGBA : 3200x720, 8bit | ||||||
| Addr Ptr | Shrd_ptr start | Shrd_ptr end | Shrd Start + MemSize(ideal) | A == B ? | Host start | Host End |
| YUV1_1 | 2948165632 | 2949373952 | 2949373952 | OK | 749830144 | 751038464 |
| YUV2_1 | 2949980160 | 2951188480 | 2951188480 | OK | 751644672 | 752852992 |
| YUV3_1 | 2951794688 | 2953003008 | 2953003008 | OK | 753459200 | 754667520 |
| YUV4_1 | 2953609216 | 2954817536 | 2954817536 | OK | 755273728 | 756482048 |
| RGBA 1 | 2994225152 | 3003441152 | Not Need | 737681408 | ||
| YUV1_2 | 3003441152 | 3004649472 | 3004649472 | OK | 795885568 | 797093888 |
| YUV2_2 | 3005255680 | 3006464000 | 3006464000 | OK | 797700096 | 798908416 |
| YUV3_2 | 3007070208 | 3008278528 | 3008278528 | OK | 799514624 | 800722944 |
| YUV4_2 | 3008884736 | 3010093056 | 3010093056 | OK | 801329152 | 802537472 |
| YUV1_3 | 3010699264 | 3011907584 | 3011907584 | OK | 803143680 | 804352000 |
| YUV2_3 | 3012513792 | 3013722112 | 3013722112 | OK | 804958208 | 806166528 |
| YUV3_3 | 3014328320 | 3015536640 | 3015536640 | OK | 806772736 | 807981056 |
| YUV4_3 | 3016142848 | 3017351168 | 3017351168 | OK | 808587264 | 809795584 |
| RGBA 2 | 3017957376 | 3027173376 | Not Need | 746897408 | ||
| YUV1_4 | 3027173376 | 3037597696 | 3028381696 | NG | 810401792 | 811610112 |
| RGBA 3 | 3028381696 | 3037597696 | Not Need | 756113408 | ||
| RGBA 4 | 3038203904 | 3047419904 | Not Need | 765329408 | ||
| YUV2_4 | 3047419904 | 3048628224 | 3048628224 | OK | 812216320 | 813424640 |
| YUV3_4 | 3049234432 | 3050442752 | 3050442752 | OK | 814030848 | 815239168 |
| YUV4_4 | 3051048960 | 3052257280 | 3052257280 | OK | 815845376 | 817053696 |
| YUV1_5 | 3052863488 | 3054071808 | 3054071808 | OK | 817659904 | 818868224 |
| YUV2_5 | 3054678016 | 3055886336 | 3055886336 | OK | 819474432 | 820682752 |
| YUV3_5 | 3056492544 | 3057700864 | 3057700864 | OK | 821288960 | 822497280 |
| YUV4_5 | 3058307072 | 3059515392 | 3059515392 | OK | 823103488 | 824311808 |
