Tool/software:
Hi Team:
On TIDL 10.00.08.00
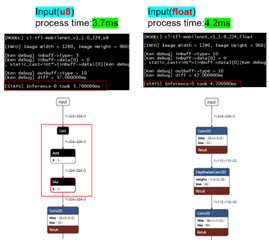
I try to convert the default model(mobilenet1v) with input = uint8 and input = float,
I found that the model with input=uint8 performs a dequantize step,
while the rest of the parts are identical to the model with input=float.
However, the model with input=uint8 actually has a shorter inference time.
I'm not sure why this symptom occurs.
Thanks for your kindly help.
Best regards,
Ken