Part Number: SK-AM68
Other Parts Discussed in Thread: AM68
Tool/software:
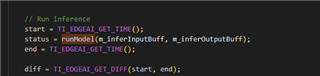
I use SDK_10.00.00.08 to do product defect detection based on SK-AM68, Running multiple models with 1920*1080 resolution。
For example, if we run 4 models with single input, the inference time of each model is 20ms. When running multiple models (4 models), the total inference time is about 80ms after actual testing. Is it possible to run multiple models in parallel, that is, run 4 models with a total running time of 20~30ms? thanks