Other Parts Discussed in Thread: UNIFLASH
Tool/software:
Vaibhav,
Based on our last meeting, the use of OSPI NAND was proposed as a cost-saving measure. However, we need evidence to ensure data reliability, especially regarding the boot firmware. Please provide documentation or test results that explain how data integrity is maintained when using AM62A with OSPI NAND—such as boot protection mechanisms, ECC, wear leveling, etc.
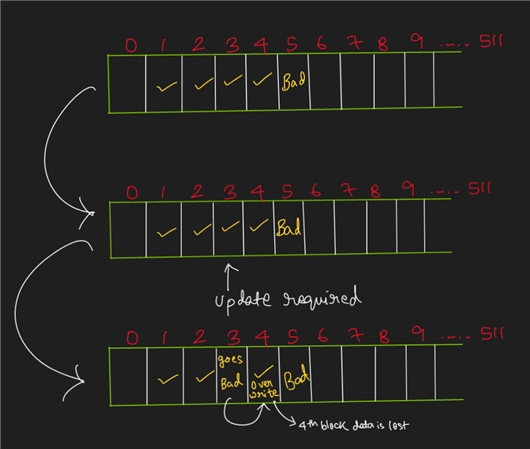
Specific bad block management has what features, such as data storge in flash bad blocks, whether this part of the data is directly lost. The other is whether the code can still be started if there is a bad block of the address.I can see we can support BBM on the ROM code but I need more details how to confirm that the binary stored in the NAND will not be loss. It can ensure still be boot normally.