
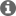


Tool/software:
In a previous question I asked whether it was possible to use the Google Mediapipe facial landmark model with TIDL, but received the answer that it wasn't practical.
I replied that I would search for the alternative model, but before doing so, I tried replacing PReLU nodes with ReLU nodes and running it.
face_landmark_relu.zip
Compile: Ubuntu 22.04, EdgeAI-TIDL-tools 10_01_04_00
Run : SK-AM62A-LP , Processor-SDK 10_01_00_05
Inference results is berow (Left is on the CPU, Right is on the C7x)

The results shows a difference in accuracy between running on CPU and on C7x.
When the input is a frontal face image, the offloaded model returns better results.
Is there any reason for this, or is it just a coincidence?
Calibration doesn't make the model more accurate than the original, right?

