


Part Number: SK-AM62A-LP
Other Parts Discussed in Thread: TIDA-010955
Tool/software:
Hello TI Dev,
EdgeAI model composer provides a training platform for arc fault where there are several model selection for arc fault as shown in figure below. I am wondering whether those numbers (200,300,700,1400) are referred to. Do they represent time step?
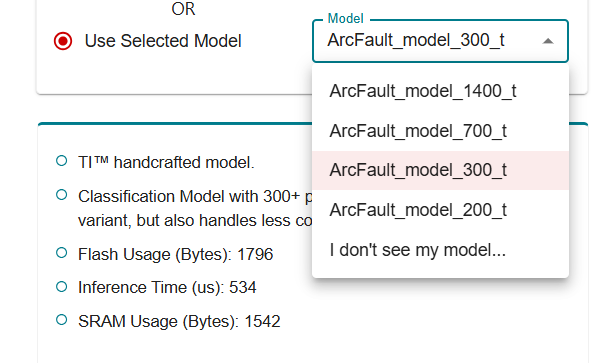
Sincerely yours,
Key



