Dear TI Employee,
The situation is that the processing time doesn't meet my requirement.
In the document SPRS691C page 18.
It tells us " a very high level of parallelism that can be exploited by DSP programmers through the use of TI's optimized C/C++ compiler "
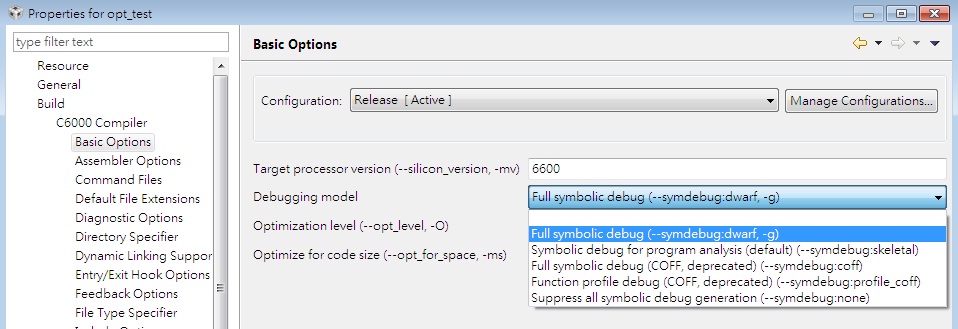
So, my optimization level is set to o2
But is there anything that can help me make my project run faster ?
Or is there anything I missed ?
Does the .out file control the eight functional units or I should control them ?
By the way, I am writing C code.
Regards,
Matt