


Hi Team Ti,
I was running this IPC QMSS Benchmarking example and found the below/following results.
[C66XX_0]
[C66XX_0] ======== BENCHMARK ATTRIBUTES ========
[C66XX_0] MessageQ setup delegate: ti.transport.ipc.qmss.transports.TransportQmssSetup
[C66XX_0] Number of processors: 2
[C66XX_0] Number of messages received: 93
[C66XX_0] Build profile: debug
[C66XX_0]
[C66XX_0] ======== MESSAGEQ BENCHMARK RESULTS ========
[C66XX_0] Average 1-way latency: 3383 (cycles/msg) 3383 (ns/msg)
[C66XX_0] Maximum 1-way latency: 3392 (cycles/msg) (# 43) 3392 (ns/msg)
[C66XX_0] Minimum 1-way latency: 3376 (cycles/msg) (# 4) 3376 (ns/msg)
[C66XX_0] Standard deviation: 3 (cycles/msg)
[C66XX_0] Total time elapsed: 595488 (cycles) 595 (us)
[C66XX_0]
[C66XX_0] Throughput via upfront allocation: Allocate all messages up front, sync cores, send all messages from core 0 to core 1
[C66XX_1] Core 1. msgs Received= 2000 time=2612776 (cycles - 2612 us). thrput=765696 [msgs/s]
[C66XX_1] cycles/msg = 1306
Now what i see on the http://processors.wiki.ti.com/index.php/BIOS_MCSDK_2.0_User_Guide#IPC_Benchmarks
is
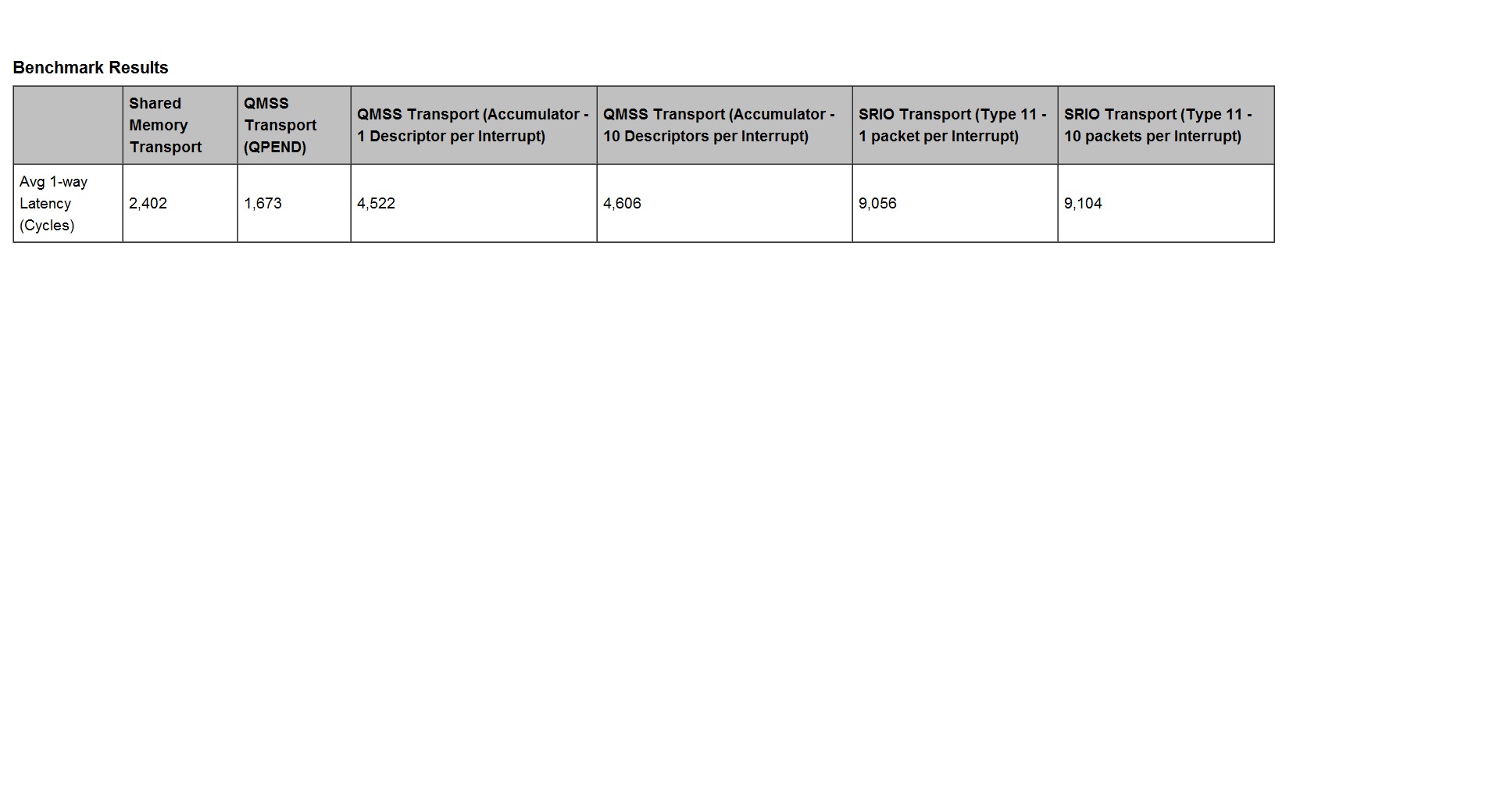
In the Table, it comes to ~1600 cycles [QMSS Transport QPEND] and in the example it is around ~3383 cycles. So I understand that Table is created from example projects [in Ti MCSDK Installation folders].
Can Someone from Ti, kindly/please explain why is this difference [in 1-way latency in terms of number of cylces/msg]?
Thanks
RC Reddy
