


Hi,
I'm trying to find the most efficient way to exchange "data" between several cores on the C6678 DSP. I've attached a figure of the basic application topology.
Background information:
We have two independent real-time digital signal processing (RT-DSP) paths for channel 1 and channel 2. The total workload of each data-plane path is partitioned among two cores (core-pipelining). Further, co-processing-cores provide different signal parameters to the RT-DSP-Tasks running on the data-plane.
Requirements:
What I mean "with the most efficient way to exchange data between cores" is in terms of minimal latency. Further, with "minimal latency" is not meant a few microseconds but rather a few core clock cycles. The size of the exchanged data packages between the cores is configurable and ranges from one single data samples (single precision floating-point) --> 4Byte up to several tenth of data samples --> max. 256Byte. The data flow between all cores is absolutely regular and invariant --> continuous data streaming application.
The hard timing constraints (for completing the entire data-plane path (RT-DSP#1 and RT-DSP#2) for a single data sample) are at least 200ns and must not be exceeded! These results in only 250 instruction cycles @1.25GHz core clock. The total complexity of the signal processing, which is completed on the data plane, is lower than 400 instruction. Partitioning the total workload among two cores results in a total workload for RT-DSP#1 and RT-DSP#1 lower than 200 instruction. That's why each single instruction cycle counts...
Solution Possibilities:
What I surely can say is that the application will not use any OS (e.g. SYS/BIOS, etc.). I would guess that an OS-based IPC mechanisms would surely take several hundreds of core clock cycles.
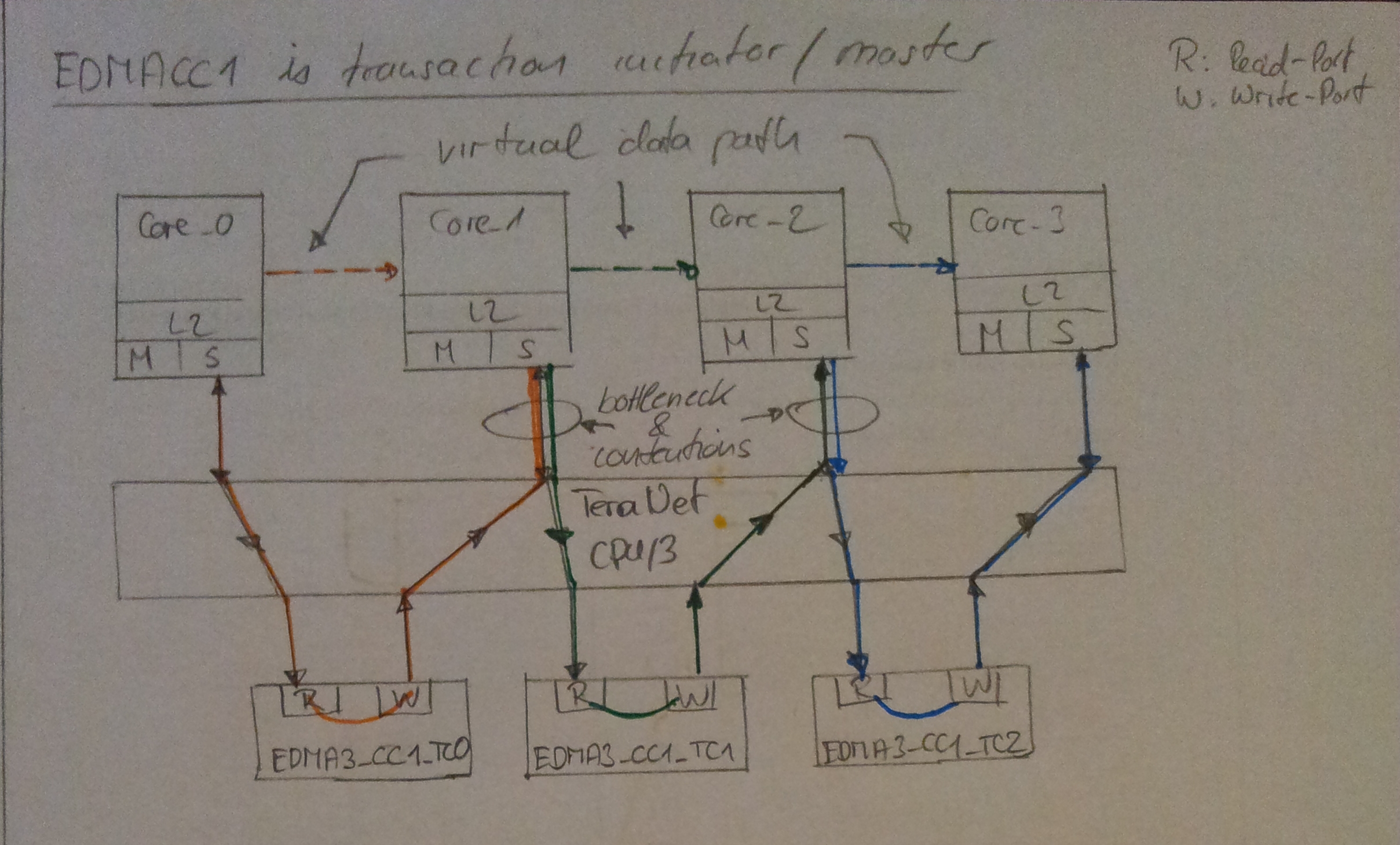
So I could get an rough overview about the C6678 architecture and have now a little idea what different mechanism for managing IPC tasks are available.
Only to name some:
- EDMA3 (-->for signaling events after data exchange completion via HW-IRQ)
- Multicore Navigator incl. PKTDMA and QM (-->for signaling events and data exchange)
- Semaphore2 hardware (-->only for signaling events. data exchange is done via shared memory)
- Notification/Signaling via SW-Interrupts (-->only for signaling events. data exchange is done via shared memory)
- Shared memory (MSMC-RAM) (-->for signaling events and data exchange)
- Direct access to local L2 memory of destination core-pack (-->for signaling events and data exchange)
- etc.
Possibly you could complete the above list with additional techniques and give me an advise what to look at first in more detail and why (ideally it should be the most promising mechanism regarding the requirements mentioned above). I try to avoid writing a benchmark application for every provided IPC mechanism.
Kind regards,
Viktor


{kind=link}