Hi,
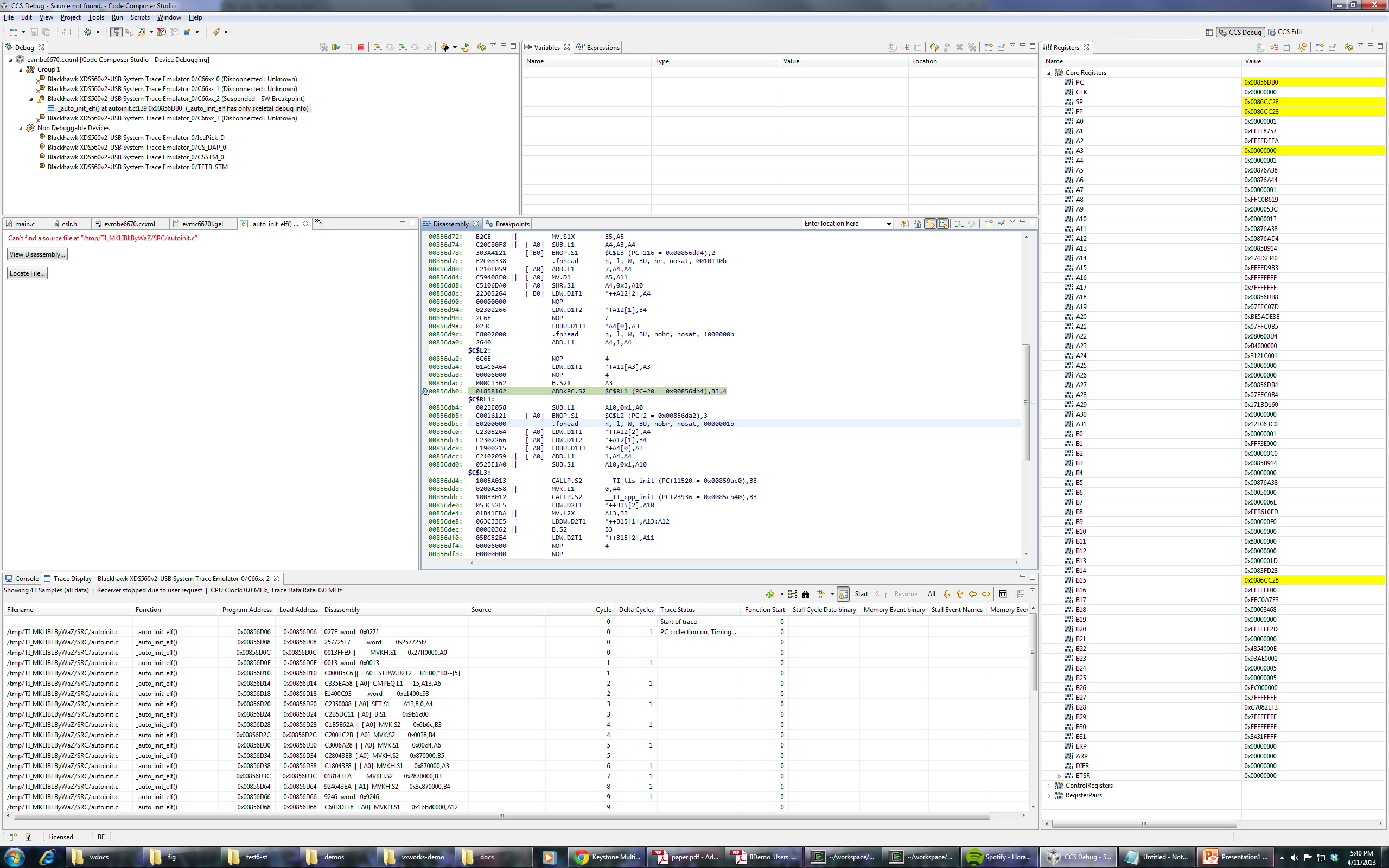
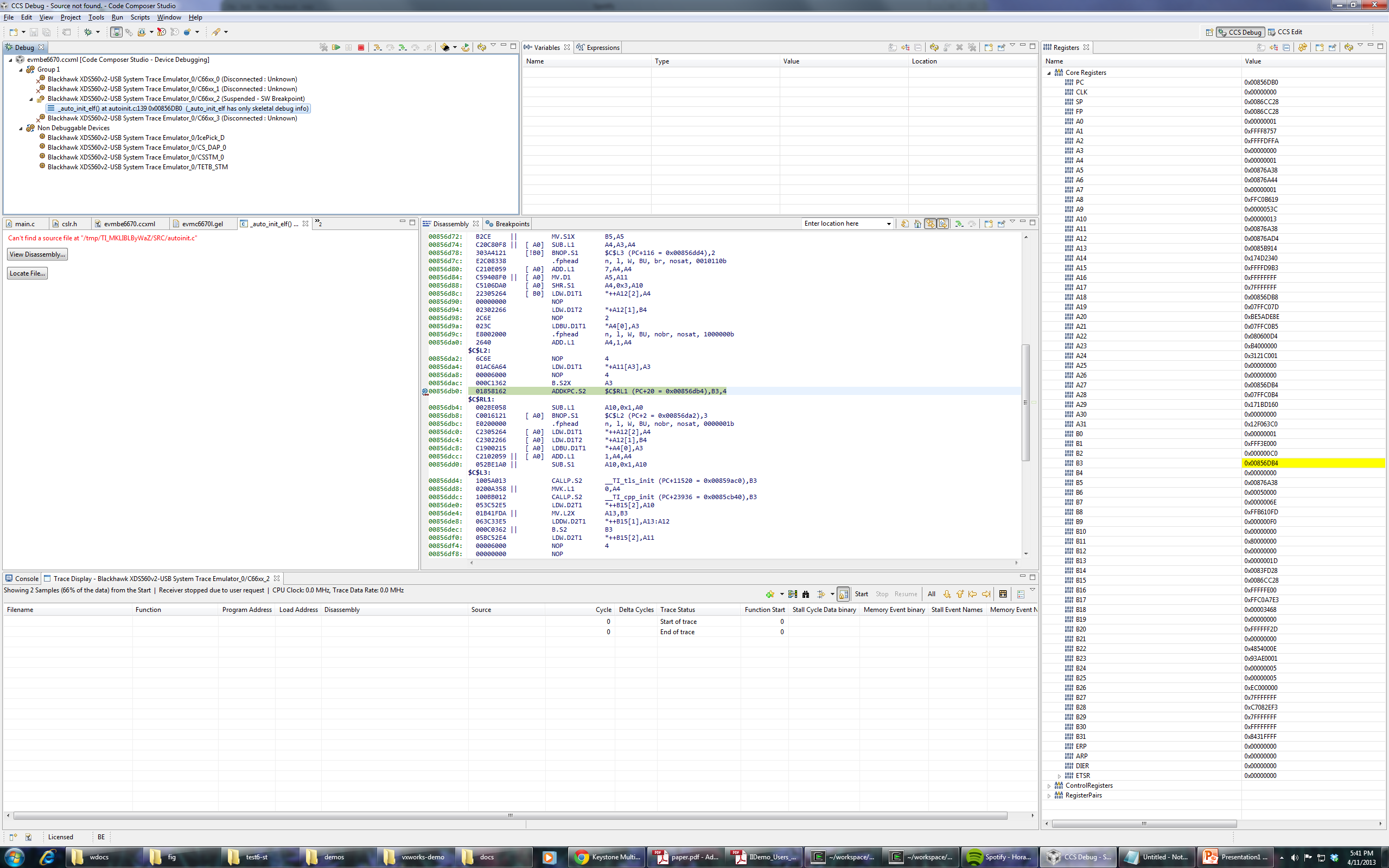
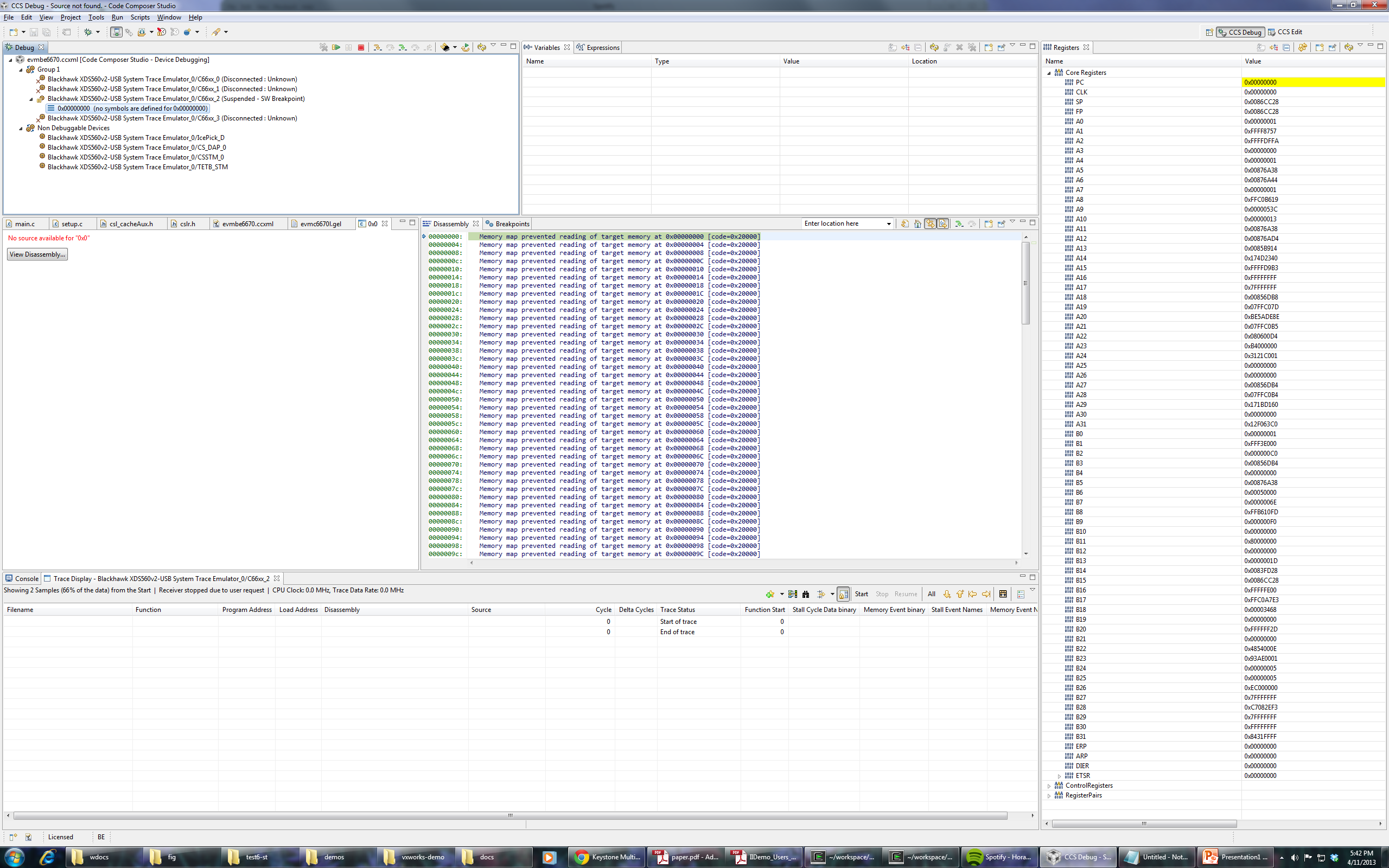
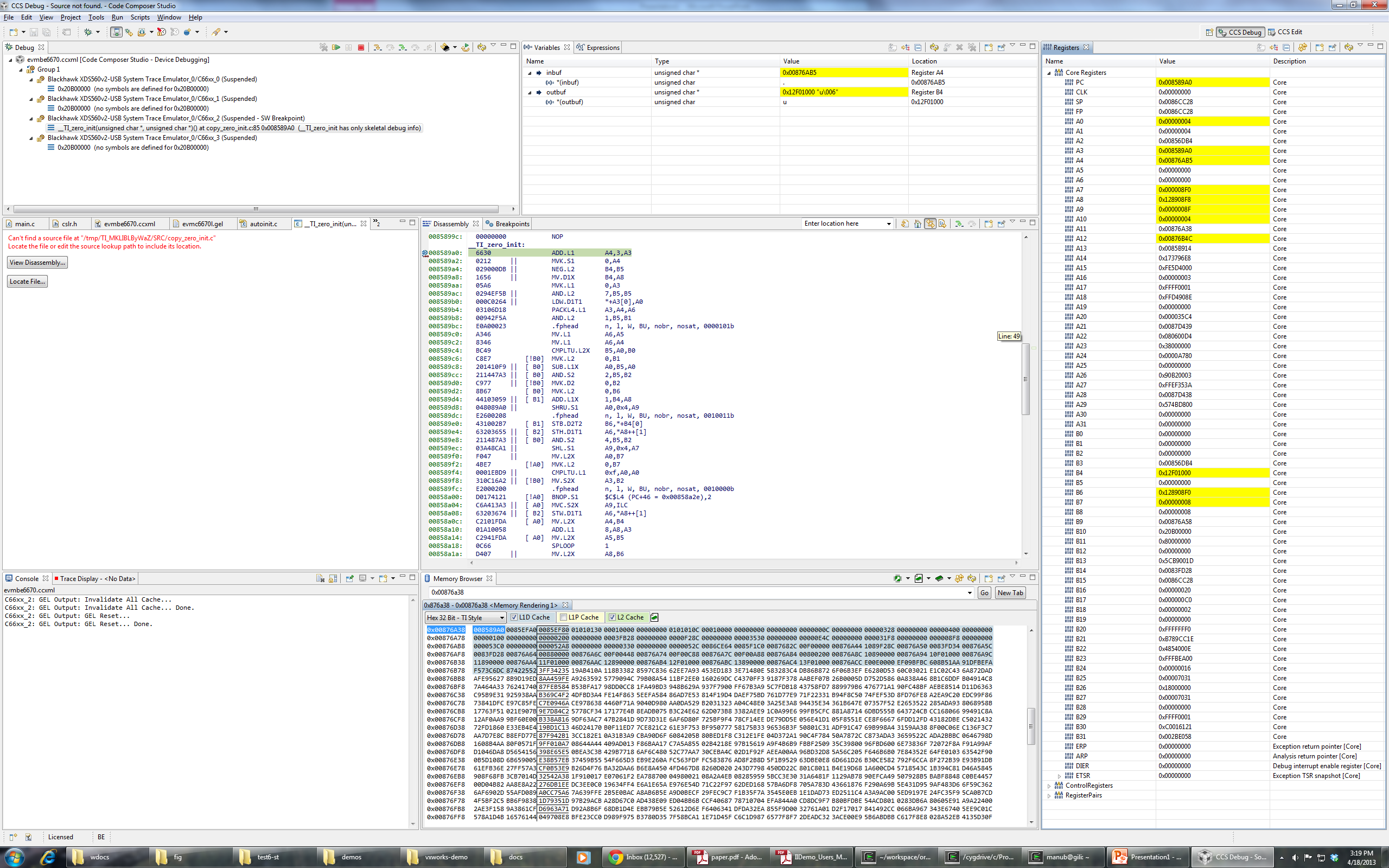
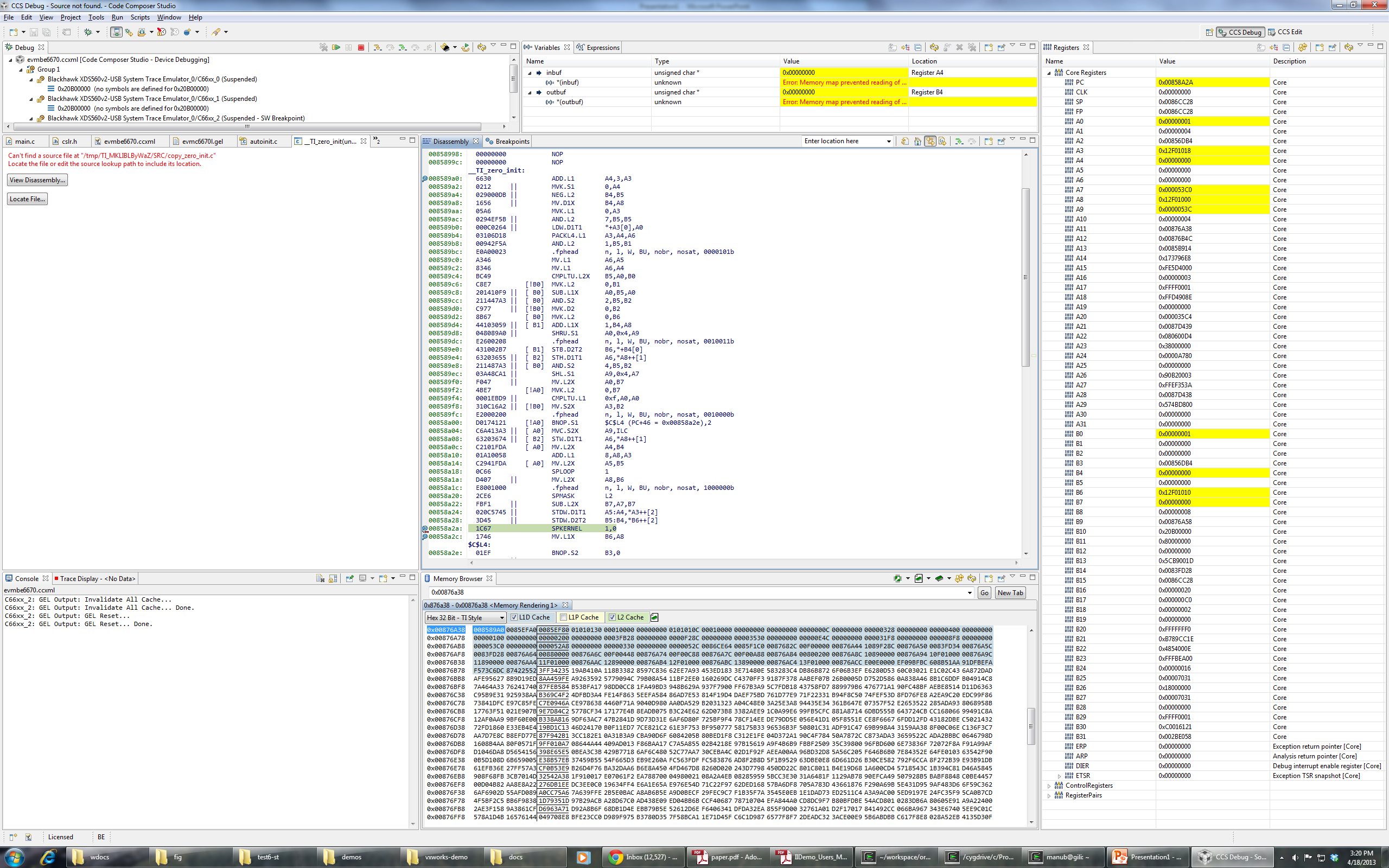
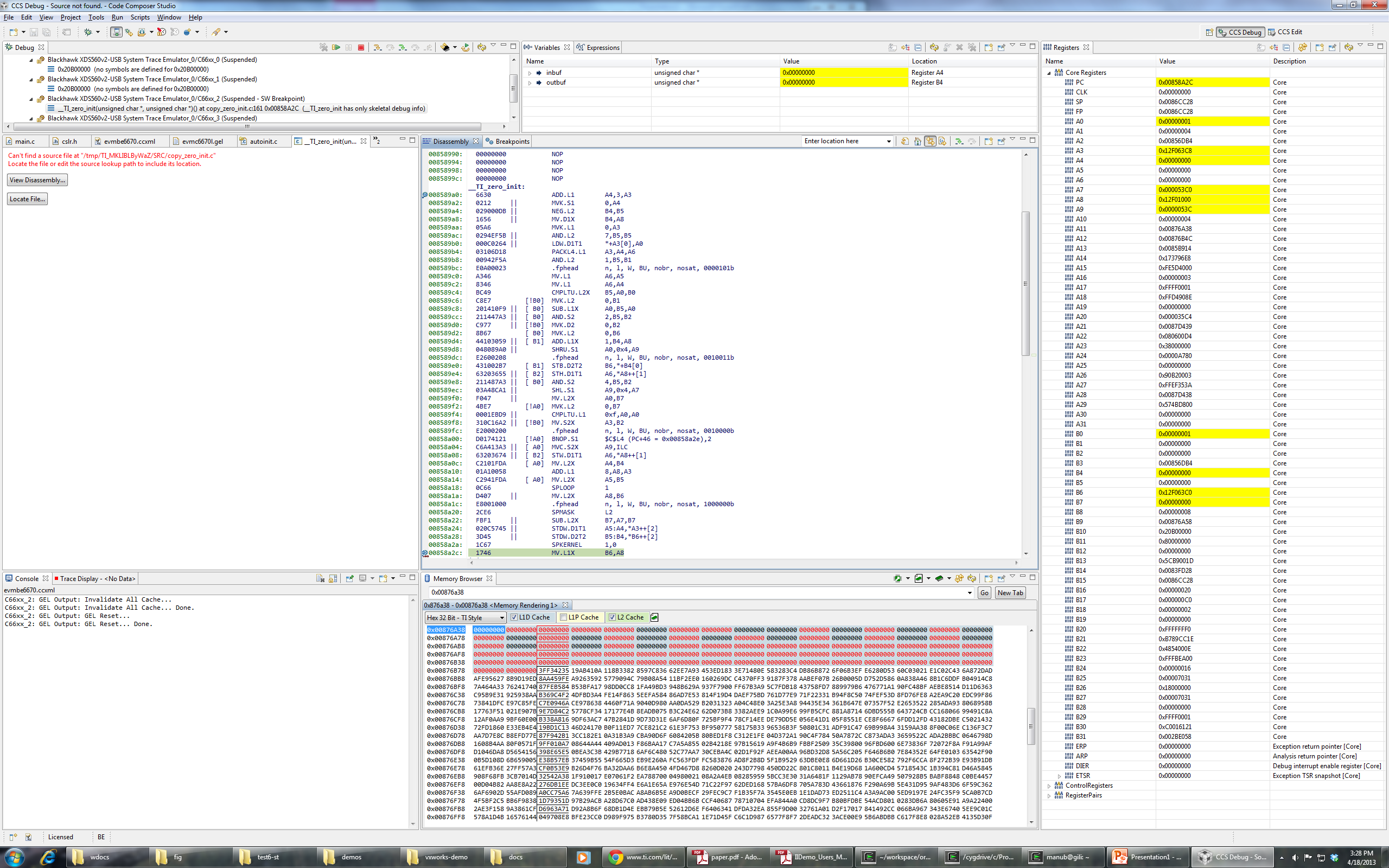
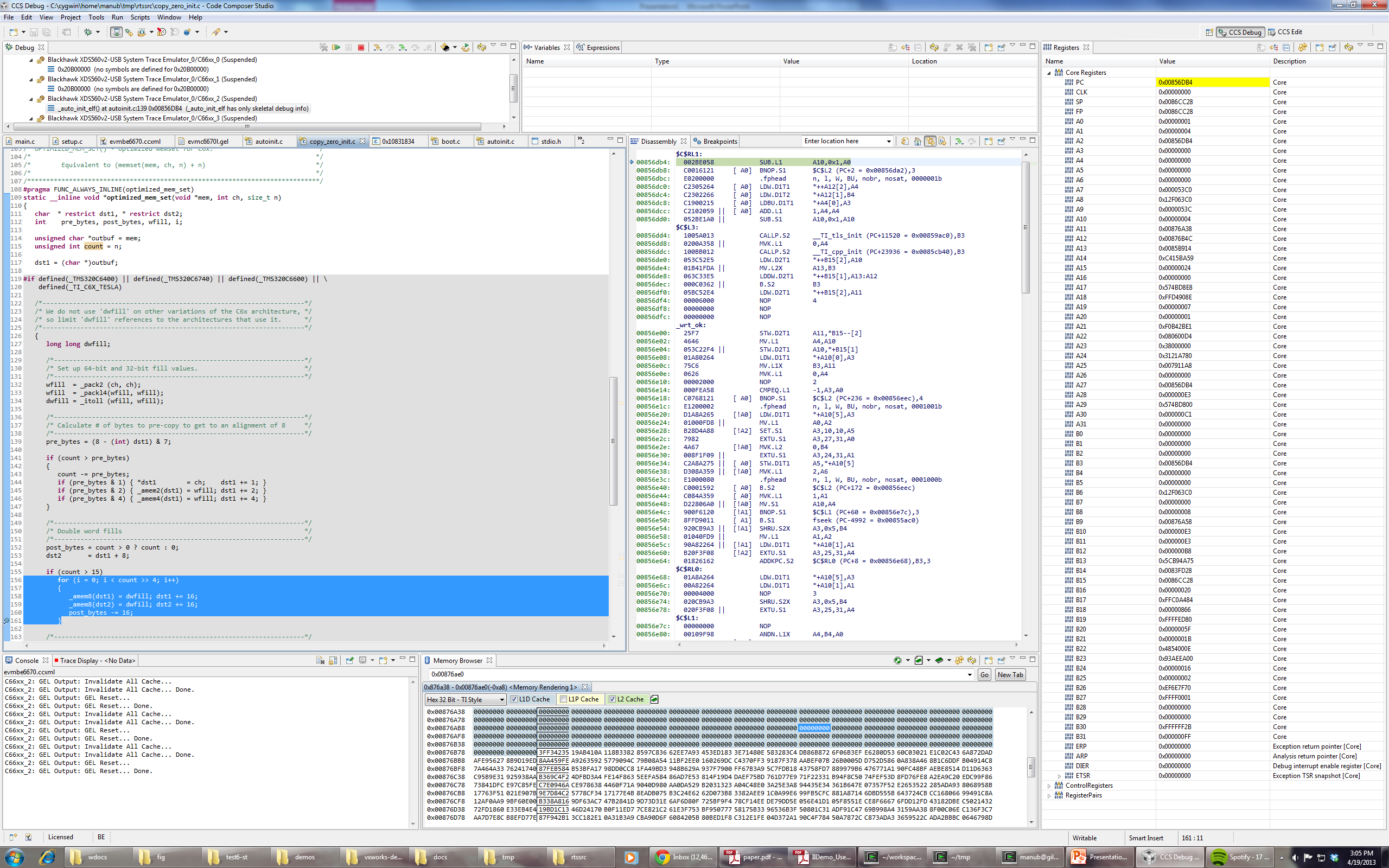
I'm trying to load the binary attached with this post on a c6670 target. (Remove everything in the extension after .out). Program load always goes into weeds on core 2, though it loads perfectly fine (breaks on main) on cores 0, 1 and 3. I tried loading without run to main, and it still goes into weeds on core 2. Any suggestions on how to debug this or what might be the problem?
Thanks.