


Hi,
I create a fileread->encode->filewrite usecase, I use the following steps to feed yuv data to encode input.
0. VdecVdis_ipcFramesFillBufInfo()
1. read yuv data from input file
2. Vdis_putFullVideoFrames()
3. Vdis_getEmptyVideoFrames()
4. VdecVdis_ipcFramesFreeFrameBuf()
I use the following steps to get h264 data from encode output.
0. Venc_getBitstreamBuffer()
1. write h264 data to file
2. Venc_releaseBitstreamBuffer()
Now the program could run successfully. But once I feed one frame per channel to encode input I will get newdata available callback twice and if the encode channel number are more than 2, the channel index larger than 1 will have each frames twice. The following figure will show the situation.
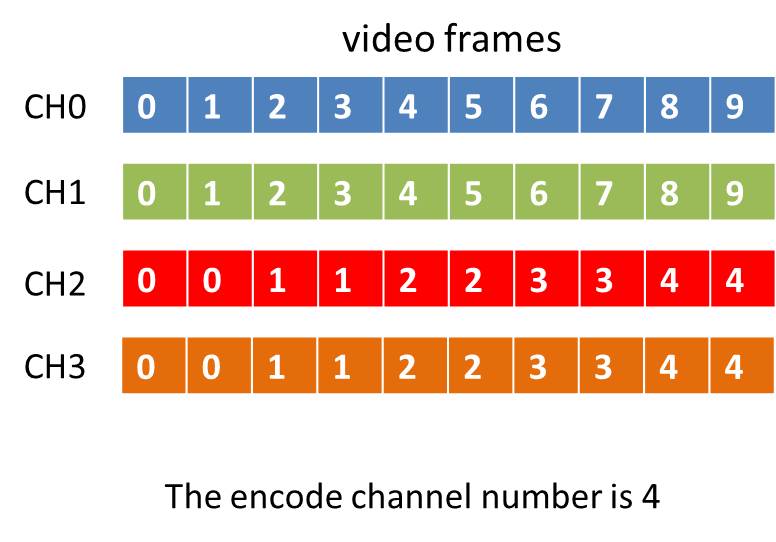
I don't know why this happens, could someone give me some advise?
