


Hi, supporters:
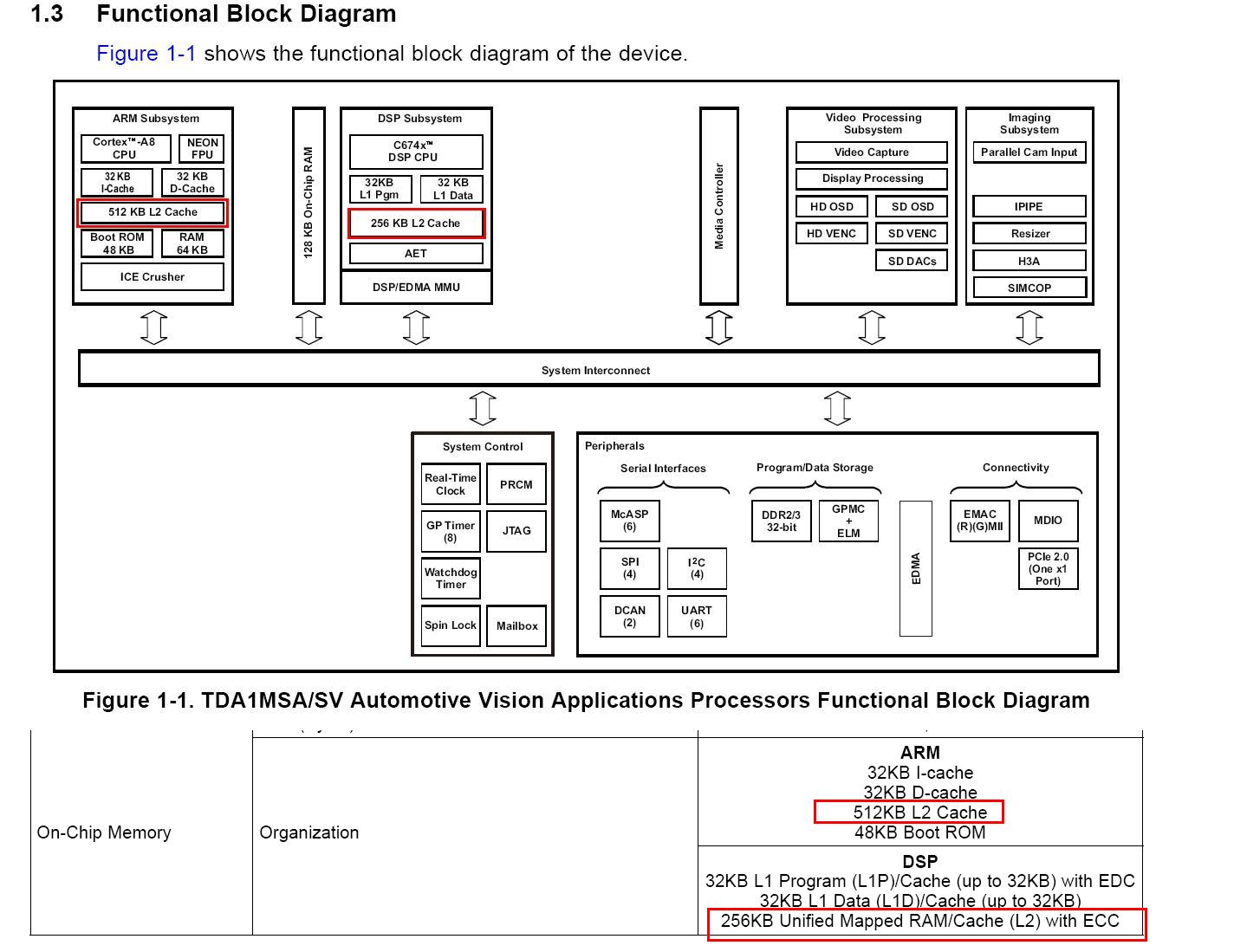
When processing images on A8, I may need to use on-chip memory (L2) to speed up the performance.
Could A8 512K L2 be used as a SDRAM for DMA+PingPong Processing just like in dsp?
Is there register or memory map to do the job?
Hi, supporters:
When processing images on A8, I may need to use on-chip memory (L2) to speed up the performance.
Could A8 512K L2 be used as a SDRAM for DMA+PingPong Processing just like in dsp?
Is there register or memory map to do the job?


