

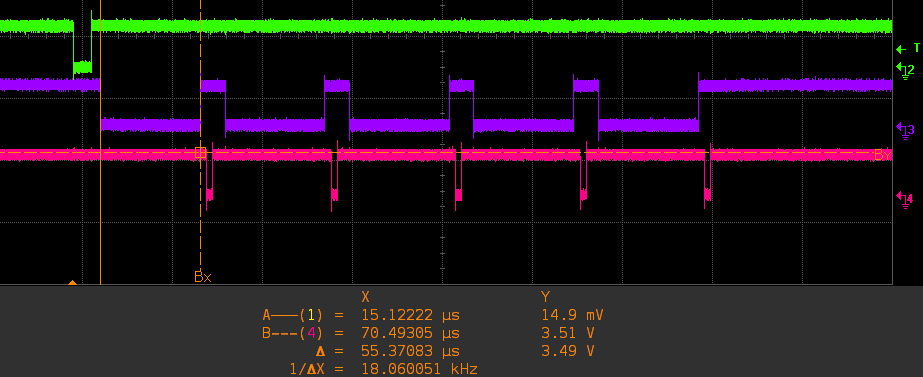
Hi, We have a custom board with a C6415T running at 1GHz and an FPGA attached to it using the 64-bit EMIF bus. I'm using an HWI triggered by an external interruption pin connected to the FPGA to post a SWI function that starts an EDMA transfer toward the FPGA by using the CSL function : EDMA_setChannel. The data transfer happens and I get a EDMA_INT interruption when the transfer is complete. But looking at what happens I'm concerned about performance issues I might encounter later on. Below is a screenshot taken on the scope that is attached to some LEDS. Green is the HWI triggered by the FPGA (low means active) Violet is the EDMA_setChannel function call (inside a SWI posted by the HWI, low means running) Pink is the EDMA completion ISR (rescheduling the SWI if required) What is happening inside the EDMA_setChannel that takes 55uS ? The only thing the function does is writing a bit in an internal register (Event Set Register). Could the writing stall if the queue for the corresponding EDMA priority is full or for any other reason ? Or is that writing always that slow ? Any suggestions on how to improve that (while keeping the CPU triggered transfer). Best Regards, Christophe

-
Ask a related question
What is a related question?A related question is a question created from another question. When the related question is created, it will be automatically linked to the original question.


{kind=link}