Other Parts Discussed in Thread: SYSBIOS, OMAP3530
Dear TI forum supporters:
I have tried to locked some data I moved via PLE in cache lines (ex. way 0) of cortex A8, but I have no idea how to use them.
I would first like to verify the correctness of data in the cache by following the article on forum like this:
http://e2e.ti.com/support/arm/sitara_arm/f/791/t/204656.aspx
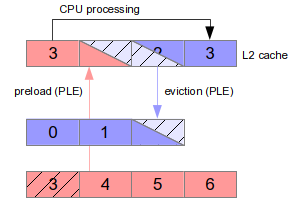
In the article, the author mentioned using a loop, events (L2 miss, and AXI), and read virtual address(ex. 0x80..)
to verify the data.
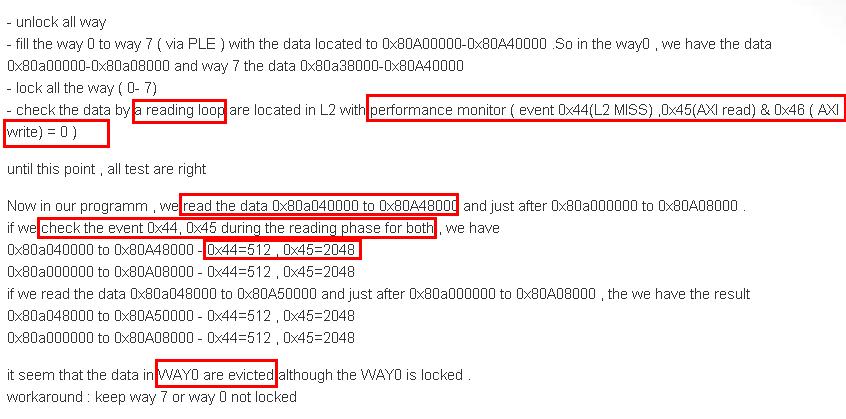
Therefore, I assume once I lock an buffer array on way 0 for example, I can simply access the buffer
address (or pointer to an array). The CPU would first check way 0 for availability, and if the data has a
cache hit, the AXI read (0x45) would increase; otherwise, the L2 miss (0x44) would increase. Is my
statement correct? If the answer is a yes, how could I check the events while read the array data?
Could someone provide a pseudo code for this ?
Thank you in advance,
Joey from Altek