Other Parts Discussed in Thread: CODECOMPOSER, SYSBIOS
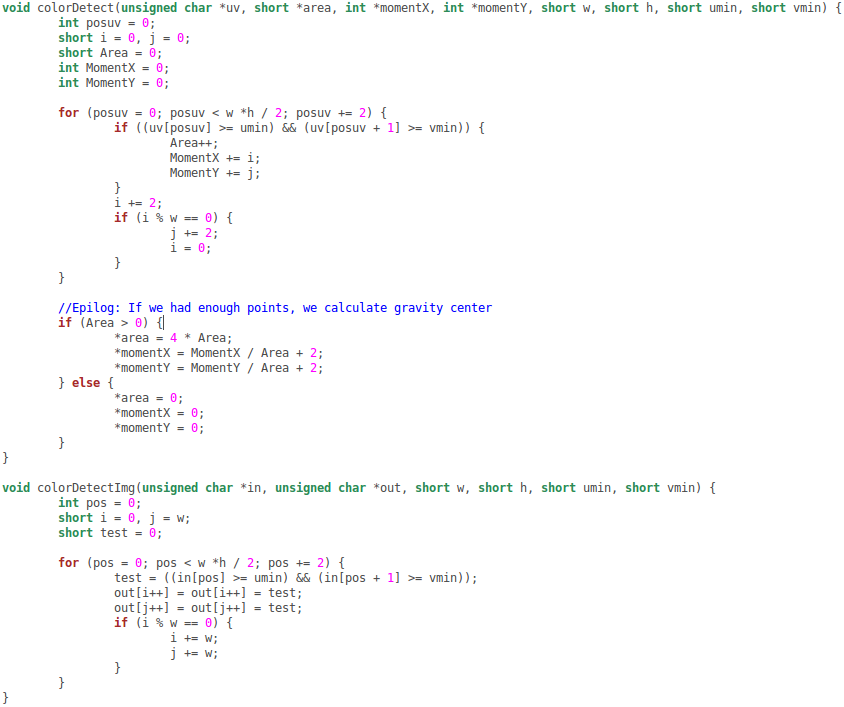
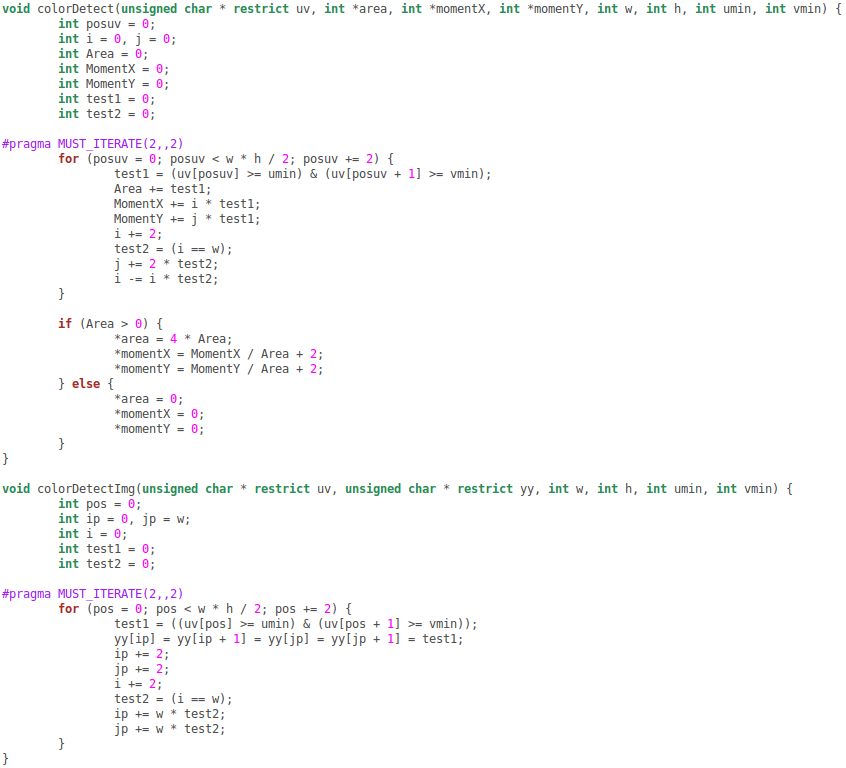
I'm running a relatively simple threshold function for a 320x240 NV12 image on a DSP C64x+. I have read the various optimization recommendations and I have tried to optimize as much as possible but the performance is still disappointing. The code looks like the following:
(I insert an image so that it's possible to read it more clearly)

Is there any other recommendation? Am I missing something obvious?