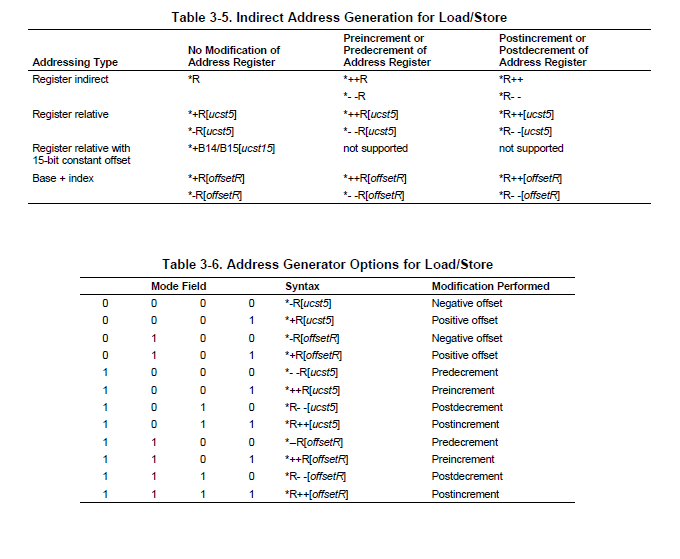
Does anyone have a good idea how to store stack pointer (and maybe some other registers) on entering a
C-function? The best I have come up with is:
uint32 global_regs[4] = {0, 0, 0, 0};
and in the beginning of the C-function a call to save_regs:
#define save_regs() \
asm(" NOP 4 ; wait"); \
asm(" STW A4, *B15--[1] ; save a4 on stack"); \
asm(" MVKL _global_regs,A4"); \
asm(" MVKH _global_regs,A4"); \
asm(" STW B3, *A4++[0] ; save return address"); \
asm(" STW B15, *A4++[0] ; save stack pointer"); \
asm(" STW A15, *A4++[0] ; save frame pointer"); \
asm(" STW B14, *A4[0] ; save data page pointer"); \
asm(" LDW *++B15[1],A4 ; restore A4"); \
asm(" NOP 4 ; wait");
It seems like getting the correct SP value (instead of extra 32-bit word - contents of A4 - in stack) stored takes quite a lot of cycles considering the simplicity of the task.
Also other good ways to do that would be appreciated.
The interrupts are running.
I'd also like to find some texts about the assembly targeted to a programmer. From the instruction set reference it's hard to find suitable
instructions with needed addressing mode options. Also all kinds of clever tricks and "phrases" are welcome.
BTW, does the
asm(" STW A4, *B15--[1] ; save a4 on stack"); \
overwrite the top of stack?
It looks like the instruction should be either "STW A4, *--B15[1]" or "STW A4, *B15--[0]" so that the write goes to the
first unused memory word. I guess TI C-compiler uses post-decrementing stack push?