Hi All
I am a new guy to use multicore DSP, when I programming on a single core on C6678 like this
#define SIZE 100
int result[SIZE][SIZE],src[SIZE][SIZE];dest[SIZE][SIZE]
init_Matrix(result);
init_Matrix(src);
init_Matrix(dest);
for(i = 0; i<SIZE; i++)
for(j = 0; j<SIZE; j++)
for(k = 0; k<SIZE; k++)
{
result[i][j] += src[i][k]*dest[k][j];
}
Someone tells me that this program computational efficiency on C6778(all eight core) can enhance more than one hundred times than single core( C6678 core0) running, if you done a good optimize.
I can't believe that, does it possible?
I saw that 22.4GFLOP/core on Corepac datasheet.
How many multiply operation can C6678 done in a cycle?
I found a table in a document,here it is
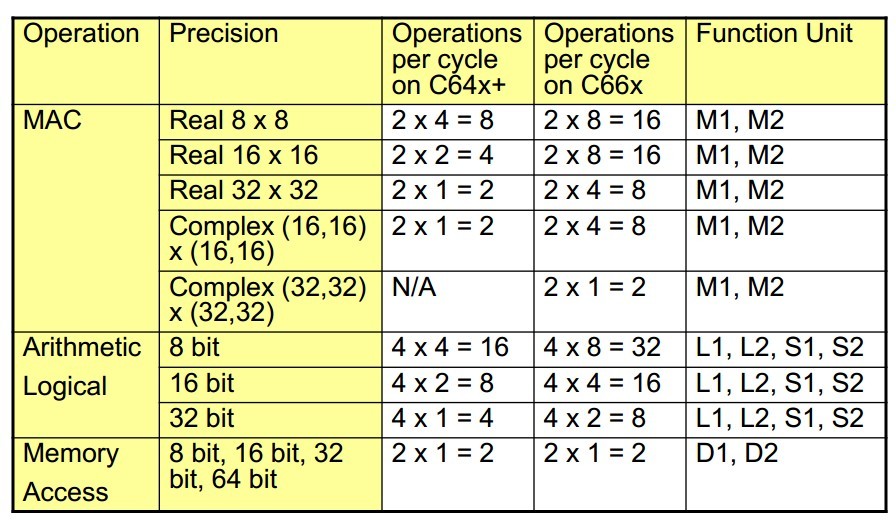
does it means that in a single clock cycle C6678 can do 64 times 32bit x32bit operation?
thus, 100*100 Matrix Multiple is about 1,000,000 times multiple operation .then it means that It cost at least 1,000,000/64 = 15625 cycle?
I do a experience on C6678 with openMP to do this work. the sorce code is here
#include <ti/omp/omp.h>
#include <c6x.h>
#include <stdlib.h>
#include<stdio.h>
#include <time.h>
#define SIZE 100
#define NTHREADS 8
unsigned long long start,finish;
void main()
{
start =0 ; finish = 0 ;
TSCL = 0;
int (*A)[SIZE], (*b)[SIZE], (*c)[SIZE];
A =malloc(sizeof(int)*SIZE*SIZE);
b = malloc(sizeof(int)*SIZE*SIZE);
c = malloc(sizeof(int)*SIZE*SIZE);
int i, j,k;
srand(time(NULL));
/*矩阵初始化*/
for (i=0; i < SIZE; i++)
{
for (j=0; j < SIZE; j++)
{
A[i][j] = rand()%10; //随机生成矩阵内容
b[i][j] = rand()%10;
c[i][j] = 0;
}
}
start = TSCL;
omp_set_num_threads(NTHREADS);
#pragma omp parallel shared(A,b,c) private(i)
{
// tid = omp_get_thread_num(); //获取当前线程的id
#pragma omp for private(j,k) //将for循环展开运算
for (i=SIZE; i > 0; --i)
{
for (j=SIZE; j > 0; --j)
{
for(k=SIZE; k > 0; --k)
{
c[i][j] += (A[i][k] * b[k][j]); //做矩阵乘法
}
}
}
}
#pragma omp critical
{
finish = TSCL;
printf("\n timecoast %ld \n",finish-start);
for(i = 0; i<SIZE;i++)
{
for(j =0; j<SIZE;j++)
{
printf(" c[%d][%d]=%4d ",i,j,c[i][j]);
}
printf("\n");
}
free(A);
free(b);
free(c);
}
}
I set the Optimization level -3
but the result is that the 1,000,000 multiple operation cost 26597707 cycles.
Did I test it in a wrong way? Or it has a better Optimization method?