Other Parts Discussed in Thread: TLK110
Hello,
Actually, we are developping a new control drive based on several dsp Sitara arm 3359 and a real time master linked thanks to an Ethercat network.
The real time master is an Intime Core with a KPA Stack.
We have developed our own DSP card which holds 2 dsp. The design of this card is really closed to the design of the 2 TI ICE Card grouped on a same card. The main difference is on the PHY component: we didn’t choose to use the Tlk110 but another Ethernet Phy LAN 8710.
I can give you some other technical details:
- My code is compiled with CCSv6 and I’m testing in debug mode with an USB Probe
- I use sdk 1.1.0.8 (I will update the sdk later)
- The XDCTools version is 3.3.6.60_core
- The SYS/BIOS is 6.41.5.54
To summarize the configuration of test we have an Ethercat network with:
- Intime master with KPA Stack
- Slave 1 with ARM3359
- Slave 2 with ARM3359
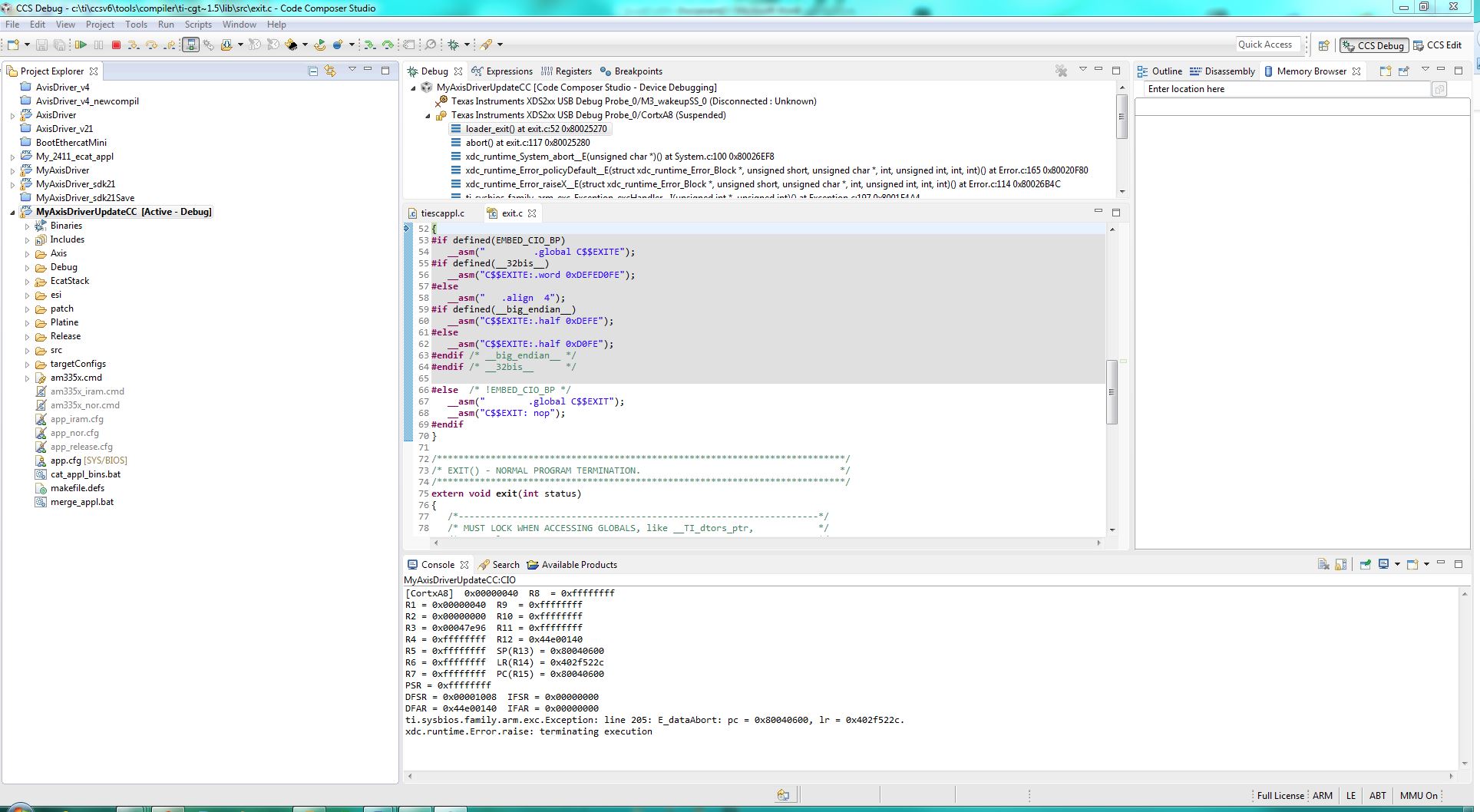
So, we launch the test: start the code in debug mode on the 2 dsp, start the master with KPA Studio, scan the bus, find the 2 slaves, attach the slaves….. After a little time, an exception occurs on the dsp1 (you can see the screenshot in attachment).
So we decided to test another configuration by inverting the order of the dsp slave on the network (slave 2 before slave1). We launch the test and…. There is no error! We can reach the operational mode and run the test during hours.
So we decided to test another configuration and only test the slave 1. We launch the test and…. There is no error! We can reach the operational mode and run the test during hours.
We have made lots of time measurements on the clock, the data…. Everything seems to be normal. We also tried to modify the value of the parameters ESC_ADDR_TI_PORT0_TX_START_DELAY and ESC_ADDR_TI_PORT1_TX_START_DELAY: these parameters don’t seem to have any effects on the data clocking.
We don’t find any reason that could explain this exception and we are really annoyed at the time.
Do anyone can give us some explanation of this exception (what does it mean, when does it normally occur), on the delay parameter (what are their role). And if someone has an idea to solve the problem, that would be wonderful!
Thanks a lot for your help.
Laurence