Hello
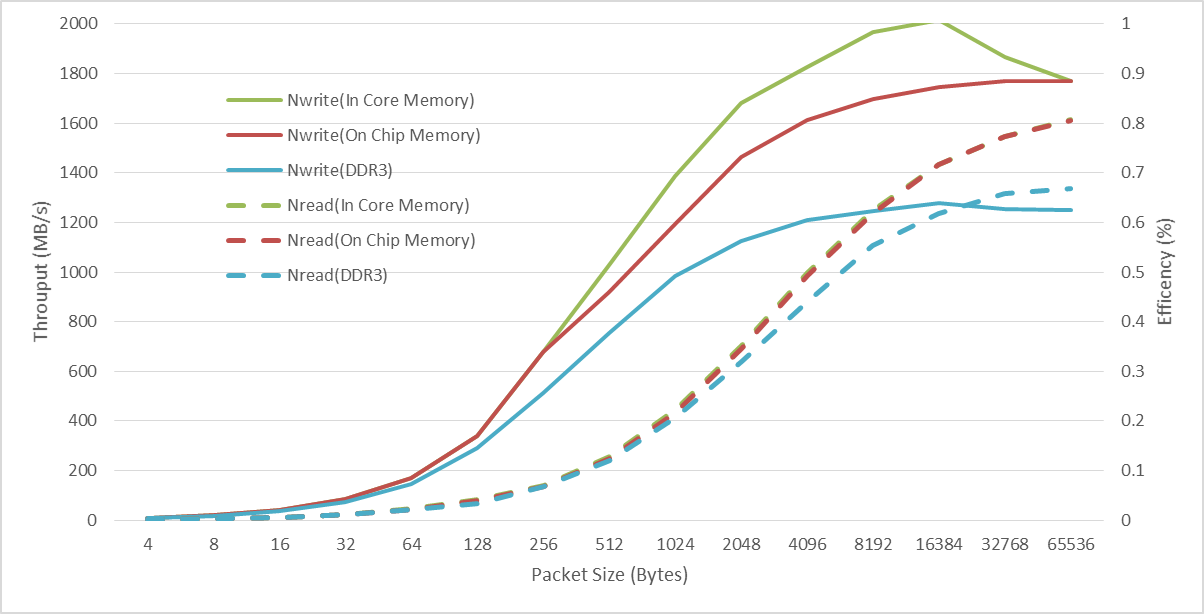
We are doing SRIO throughput test on K2H EVM. The measurement is based on board to board through SRIO switch by using NWrite and NRead packet in 4 lanes 5Gbps mode. The theoretical link rate is 2000 MBytes/s without overhead.(4*5Gbps*0.8/8=2000 MB/s)
The throughput is calculated by: Number_of_Bytes / DSP_clock_MHz / elapsed_cycles. The elapsed cycles are the number of cycles between the point setting LSU and got completion code from LSU_STAT_REG, as showing below.
t_start = _itoll(TSCH, TSCL); KeyStone_SRIO_LSU_transfer(&lsuTransfer); uiCompletionCode= KeyStone_SRIO_wait_LSU_completion(0, lsuTransfer.transactionID, lsuTransfer.contextBit); t_stop = _itoll(TSCH, TSCL); t_total = (t_stop - t_start) - t_overhead;
In the condition that the source and destination are both L2 SRAM, The NWrite can reach speed higher than 2000MB/s, which is 2015 MB/s.
Can you tell me what is the reason of the measured SRIO speed can be higher than theoretical one?
The following figure shows the performance we measured.
Thanks
Xining