Part Number: AM5728
Other Parts Discussed in Thread: SYSBIOS, AM5728
Tool/software: TI-RTOS
Hello,
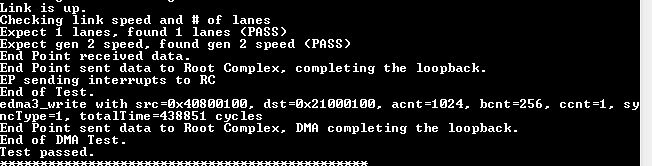
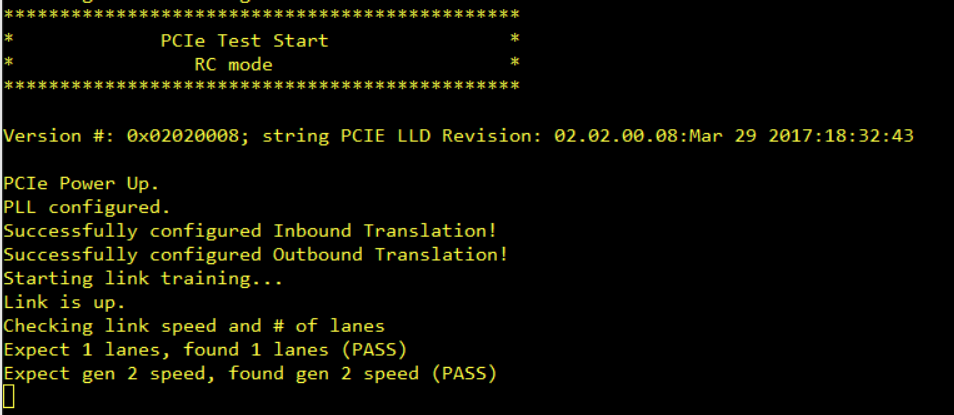
we're using the 2 PCIe lanes of the am572x to connect to an FPGA in form of a PCIe x2 GEN2 connection. am572x is RC. The configuration and utilisation of the PCIe RC is done on DSP1 core using TI-RTOS with sysbios vers. 6.46.0.23, edma lld vers. 2.12.1 and pcie code derived from the pcie example driver code. The connection works reliable and stable. We see data request TLPs arriving at the FPGA in 64 byte chunks which is a pitty, since to my knowledge at least 128 byte should be possible for the sitara. But even considering the overhead generated by these really small requests we don't achieve the estimated bandwidth.
Our tests show that we only get around half of the theoretical netto bandwidth. If we use only one lane or if we switch to GEN1 instead of GEN2 in both cases the bandwidth drops to nearly half, so we can assume that both features (2 lanes, GEN2) are actually working. We're doing EDMAs from PCIe realm into DSPs L2 RAM or into OCMC RAM. Both result in half of the theoretical netto bandwidth.
Is there some benchmark data we can compare our approach with, to verify our findings and reject possible configuration issues?
Best,
Tim