Part Number: AM3358
Tool/software: Linux
Hello,
We wanted to ask help on how we should address this issue since we don't know whether this kind of behavior is expected in the specs or not.
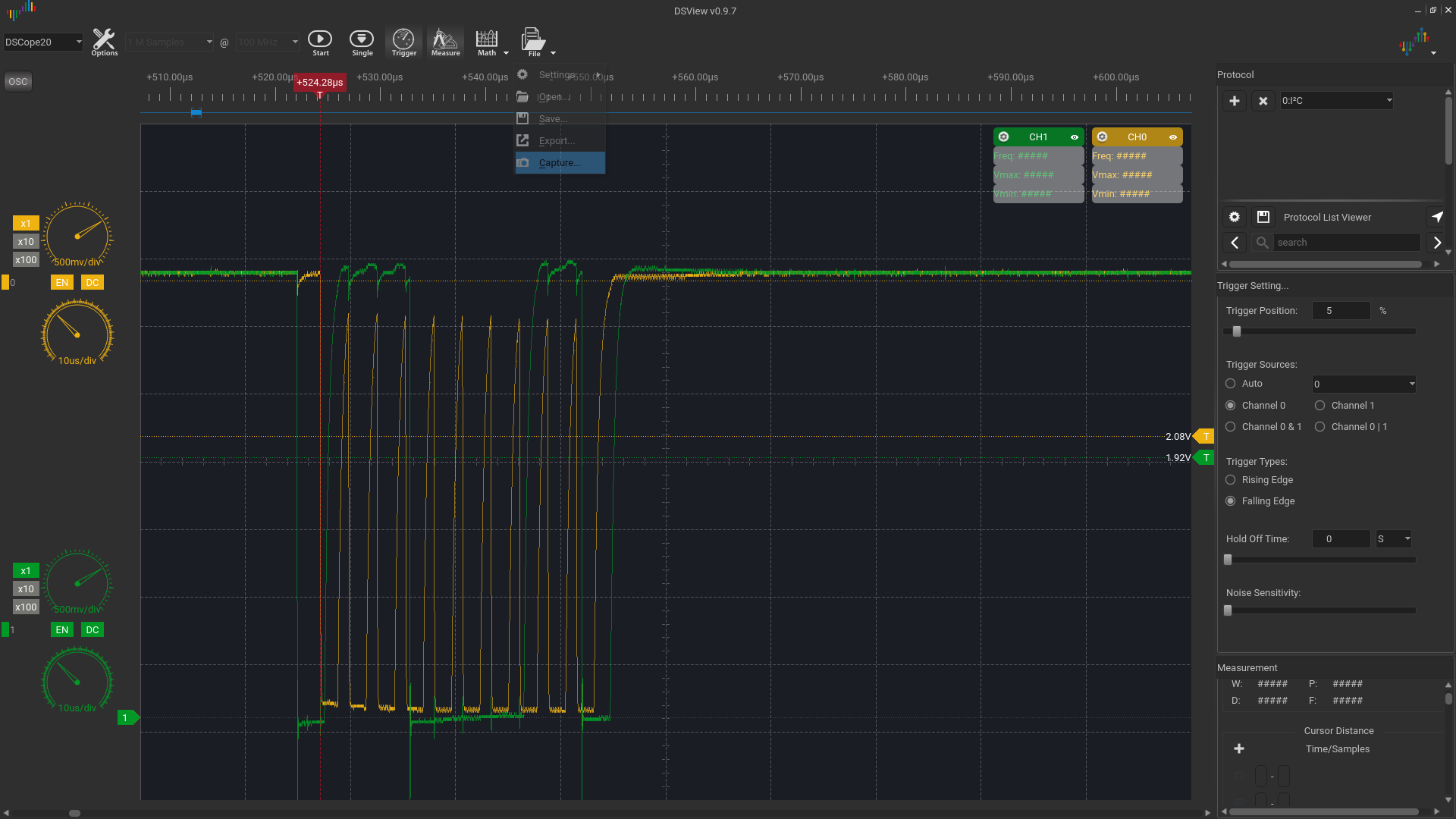
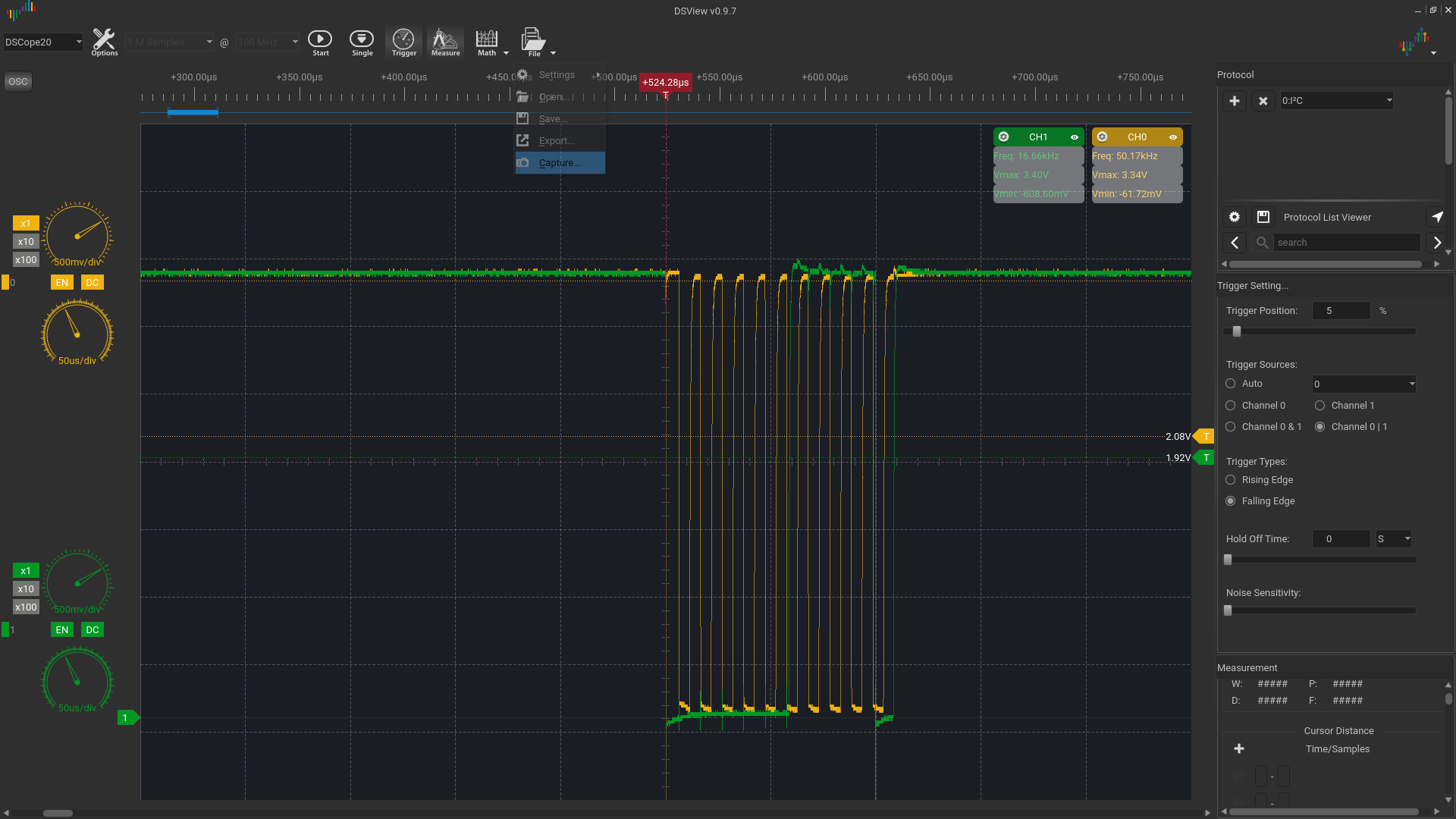
We started by noticing hard freezes after connecting some i2c gpios expanders we then moved to removing the kernel drivers mapping in the device tree and started probing using i2cdetect -y -r <i2cdev-num>.
with just one device.
We managed to recreate the problem by just randomly shorting to ground sda/scl continously during the i2cdetect probes, we may have, in this way, reached an annoying situation
Reducing the clock seemed to benefit reducing the number of freeze events.
We would like to understand whether
a) this is expected and we should provide protection on our external circuitry in case these events are going to occour.
b) is a kernel bug
c) is some hardware bug
d) something else.