Dear Champs,
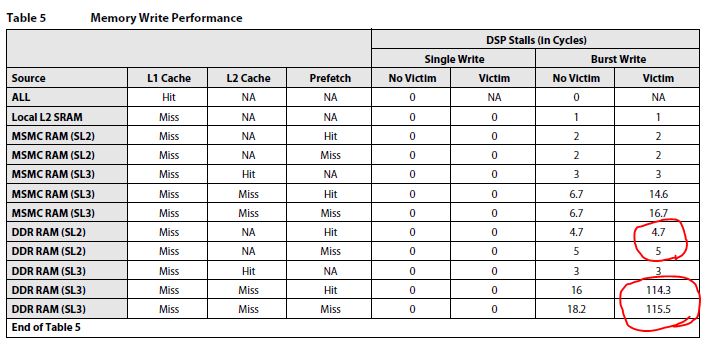
My customer is looking for the data of L2 memory latency.
Could you please let me know the L2 cache/ram, MSMC memory and external DDR3 memory latency of C6678?
And also, when core0 access to L2 cache/ram of core1, what is the memory latency in this case?
Thanks and Best Regards,
SI.