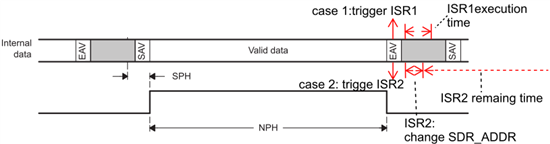
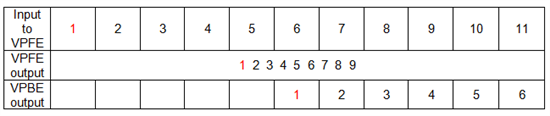
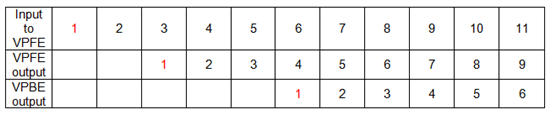
Other Parts Discussed in Thread: TVP5146
Hi All,
I would like to ask a basic question on Ping-Pong implementation.
The CCDC of VPFE accepts a continuous stream from BT.656 output image sensor, do the de-interlacing and put it into somewhere in the DDR2 memory…
But, does it turn back around?
If it continues to output to the memory starting from a certain address, incrementing the target address counter pointer after every field (or frame), then after a short period there will be no empty place in the memory left with past (historical) frames occupying all the space.
Obviously this could not be the way VPFE works. To a beginner like me, I am just seeking the way how VPFE coordinates with VPBE, or more generally, frame processing algorithms to efficiently make use of the memory space.
I would imagine that a possible scheme is to allocate two blocks of memory, when VPFE is writing to one VPBE reads from another, and this is would be a continually alternating process.
Pinning down this to detail one need
1. A way of alternatively change VPFE’s target address and VPBE’s source address.
2. A way that VPFE notifies VPBE of its completion, and vice versa.
In the scenario of more general video processing algorithm, changing VPBE above to the “algorithm function”:
1. A way of alternatively change VPFE’s target address and function’s reading address.
2. A way that VPFE notifies the function of its completion, and vice versa.
How this could be done? I wish to know how the registers and interrupt vectors need to be set in order to achieve this. And at my best hope, is there any code example for the abovementioned process?
I appreciate any help on this.
Sincerely,
Zheng