Hi!
I am struggling to get a decent speed from an SPI transfer. I need to transfer about 2k in smaller chunks using 24MHz SPI clock as MASTER.
Between the bytes of a chunk (maybe 32 to 128 bytes), the CS must be active all the time. Before and after the bytes there should be about 1 to 4 clock periods to the CS edge. The bytes within a chunk I expect to be transfered back-to-back.
I am using TI-RTOS and the pdk_am437x_1_0_13 (I haven't found any difference to the latest pdk in SPI code).
I am using DMA. In the cfg file I added Spi.Settings.useDma = "true";
like this:
/* Load the spi package */
var socType = "am437x";
var Spi = xdc.loadPackage('ti.drv.spi');
Spi.Settings.socType = socType;
Spi.Settings.useDma = "true";
I actually need to use 2 SPI units (not channels) but that does not matter, anyway my init code is like this:
static EDMA3_RM_Handle edma_handle;
void spi_preinit(void)
{
EDMA3_DRV_Result edmaResult;
SPI_v1_HWAttrs spi_cfg;
uint32_t i;
edma_handle = (EDMA3_RM_Handle)edma3init(0, &edmaResult);
if (edmaResult != EDMA3_DRV_SOK) {
UART_printf("EDMA init failed!\r\n");
}
for(i=0;i<2;i++) {
SPI_socGetInitCfg(i, &spi_cfg); /* Get the default SPI init configuration */
spi_cfg.chnCfg[0].csPolarity=MCSPI_CS_POL_LOW;
spi_cfg.chnCfg[0].dataLineCommMode = MCSPI_DATA_LINE_COMM_MODE_6;
spi_cfg.chnCfg[0].tcs = MCSPI_CH0CONF_TCS0_ZEROCYCLEDLY;
spi_cfg.chnCfg[0].trMode=MCSPI_TX_RX_MODE;
spi_cfg.edmaHandle = edma_handle;
spi_cfg.dmaMode = true;
spi_cfg.chNum = MCSPI_CHANNEL_0;
spi_cfg.chMode = MCSPI_SINGLE_CH;
spi_cfg.rxTrigLvl = 8;
spi_cfg.txTrigLvl = 8;
SPI_socSetInitCfg(i, &spi_cfg); /* Set the SPI init configuration */
}
}
The actual transfer is started like this
SPI_Transaction transaction; /* SPI transaction */
transaction.count = len;
transaction.txBuf = &spi_txbuf[0];
transaction.rxBuf = &spi_rxbuf[0];
SPI_transfer(spi_handle[num], &transaction);
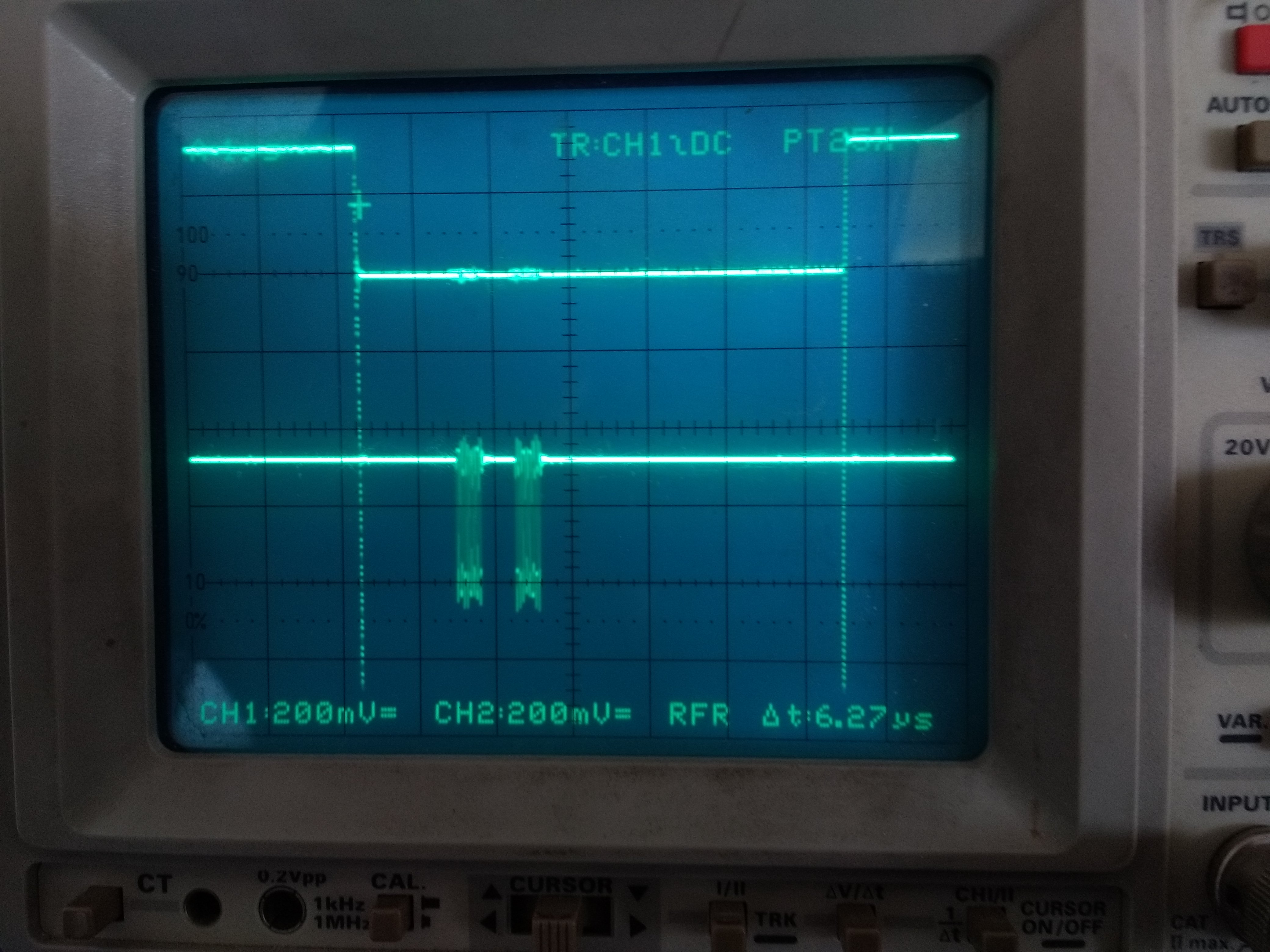
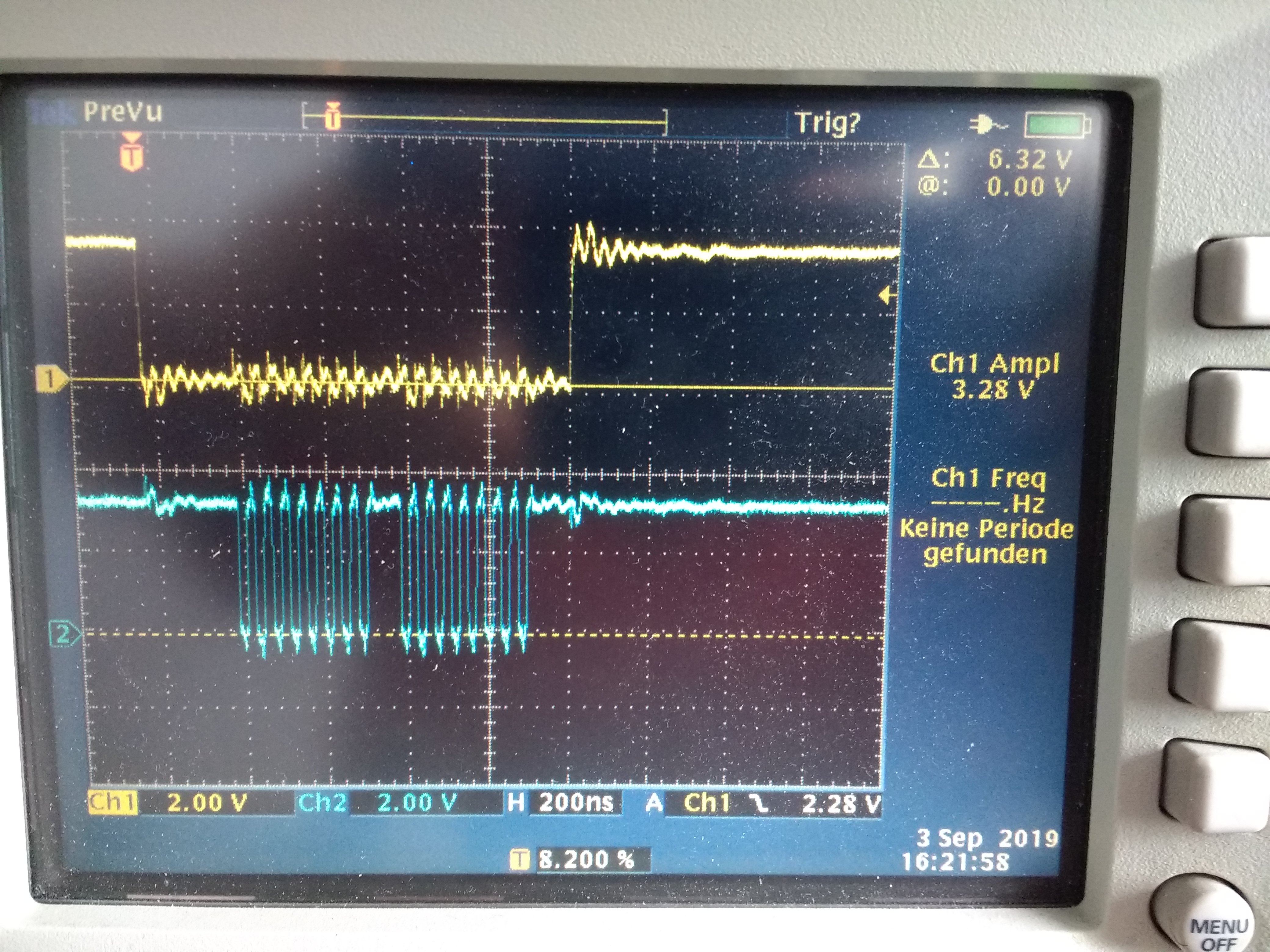
What I see is that for every byte transfered, I have the same time as idle time where nothing is transfered which already cuts the transfer speed in half, regardless of the transfer length.
And then before the first byte is transfered, after the CS going low, there is a huge delay of about 1.5us.
And then after the last byte is transfered, before the CS going high, there is a gigantic delay of about 4us.
What am I doing wrong or is this already the best this processor can do, despite using DMA?
I already tried a coupe of things. For example using MCSPI_MULTI_CH decreases the CS delay but then the CS goes away in between the bytes and also it does not reduce the gap between them. Without DMA is is much worse, something like I found in an older post where some poor guy is having a similar problem, but although the topic is marked as "solved" there is no help or solution there.
https://e2e.ti.com/support/processors/f/791/p/763016/2821395
Best regards,
Manuel Köppen
In the scope picture, the upper plot is CS, the lower is CLK.