Part Number: EVMK2H
Other Parts Discussed in Thread: MATHLIB, SYSBIOS, TEST2
Hi TI,
1. Do you have any example of benchmarking program to comapare the performance of DSP and ARM? We want to study which tasks to be run on DSP/ARM.
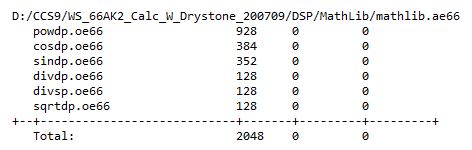
2. I try to implement a small program invlove mostly mathematic calculation, my expectation is DSP should be faster (as stated in TI DSP Benchmarking - SPRAC13). However what I see is that the ARM execution time is faster. My program is just run after loading GEL file, no specific setting for either DSP or ARM. What could be the reason of the observe performace?
3. Is there any reference or guideline on which program should be run on DSP/ARM?
Thanks a lot.