Part Number: TDA4VM
Other Parts Discussed in Thread: PROCESSOR-SDK-J721E
Hello,
I downloaded a C7x training at version 0.5 which I got from the PROCESSOR-SDK-J721E v6.1 page : PROCESSOR-SDK-RTOS-J721E_06.01.01.12 | TI.com
Is a new version of this training available or planned? If planned, can you give an approximate date of availability?
In this new version, will the advanced examples contain their documentation?
Is it possible to get the documentation of these examples now, even if it is not finished yet?
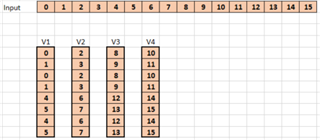
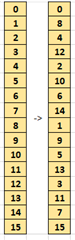
An example on FFT (c7x_fft1d_16bit) interests me a lot but there is no documentation or even comments.
Thanks a lot,
Clément