Hi
we research real-time problems in our system.
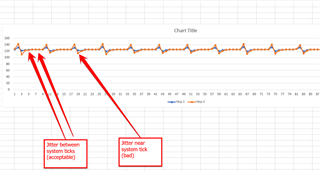
The idea is to test task reaction time to interrupt (via semaphore port) and measure jitter in task wakeup time.
Setup:
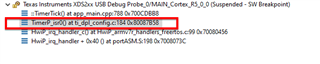
125 uSec interrupt that posts semaphore to task, whcih in turn posts another semaphore.
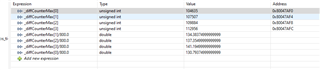
CPU time stamp counter is sampled in 2 places/tasks. Each time after semaphoreTake.
In total we have 2 hop, namely semaphore posted from ISR, tasks wakes up, samples time and posts semapore to the next task at the lower priority, whick samples time again.
We measure difference in time stamps that represents jitter in task wake up.
With each new "hop" jitter increases, there is a visible correlation between system tick (1 mSec) and jitter.
It looks like Tick notification takes too much time or CPU is just slow.
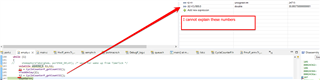
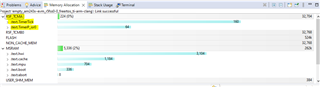
I checked that DDR is cached and both I/D caches are turned on.
Is it possible to review SOC configuration, maybe some PLL/Frequency is not set correctly?