Other Parts Discussed in Thread: BLE-STACK, UNIFLASH
Tool/software: TI-RTOS
Hello,
I too seem to be facing a similar issue to the related post :
https://e2e.ti.com/support/wireless-connectivity/bluetooth/f/538/p/795870/2948589#pi320995=2
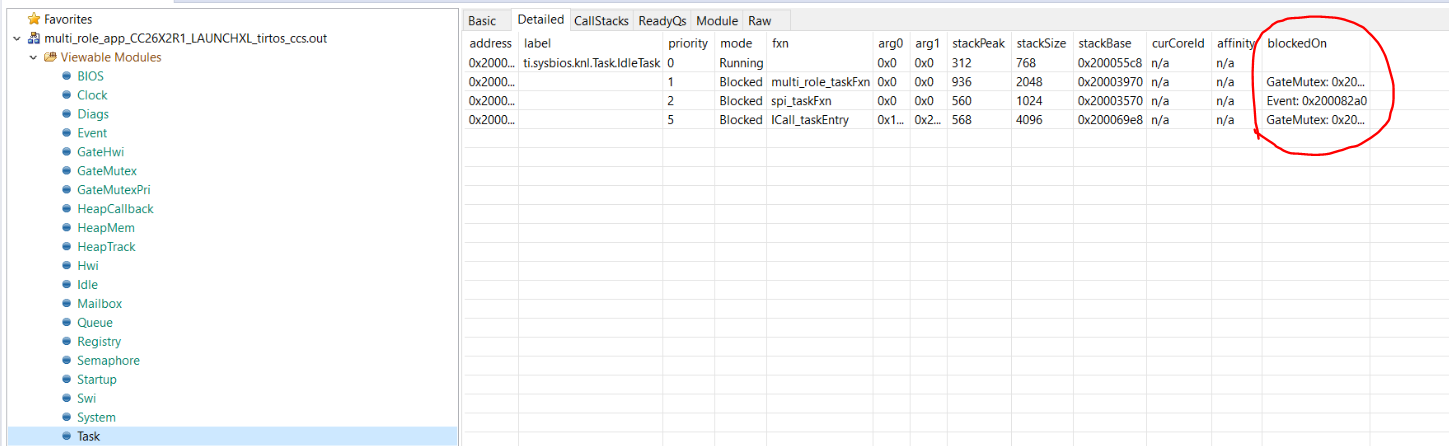
The code executes indefinitely and then suddenly comes to a halt. It may take for like hours or at times maybe within an hour. I check to see if the stack is getting overflow ( which had occurred to me earlier). But this time, the stack usage of the tasks is less than 80%. The code does not get stuck in any infinite loop nor any spinlock situation which has been verified.
The relating post mentions of doing many I2C_tranfsers, and my project does implement a lot of SPI_transfers. So I checked to see if any memory leaks may be causing this. That too was not the reason, since all of the mallocs are being freed properly and everything.
What could be the reason then ? Could it be similar to the issue faced in the releating post - "data access error". If so, what could the possible reasons be for this ?
Could the number of Spi transfers be causing a Hwi stack overflow eventually a some point? I have put it to run in debug and with ROV enabled, but as it says it takes a long time for the "stopping" to occur.
Regards,
Shyam