Part Number: CC2652R
Other Parts Discussed in Thread: Z-STACK, CC2538,
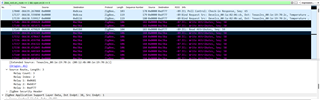
There is a fault (appears to be either a race condition / use of undefined memory) in TI"s source routing implementation. Specifically under certain situations the MAC layer destination used when sending a packet with a source route is incorrect. It is addressed to the device that will receive the packet, not the next relay.
The packet contains the correct source route information (as it should the coordinator has the source route in it's DB and it's not expired). It is however addressed to the wrong device.
I've circled the incorrect MAC destination field and put a line next to the correct value (the source route relay). The packlets highlighted in black are those that have been incorrectly addressed by the ZC.
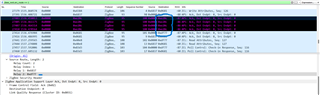
This is a regular occurance on our ZNP (simplelink) project that uses Source Routing for 99%+ of all communication. It does this because the table is large, and the source route expiration is huge. This issue is most likely to occur when many devices are communicating at the same time.
I've done some debugging and currently suspect the problem is around or in the call to NLDE_BuildSrcRtgFrame in NLDE_DataReqSend in the libZstack blob. However that is dificult to say with certainty due to the closed nature of the blob.