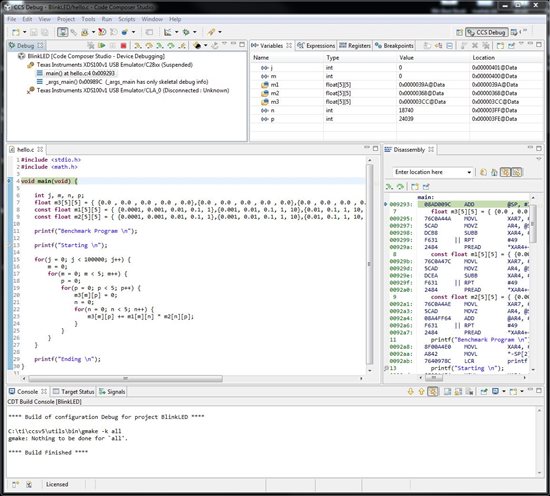
I want to benchmark the F28069 Piccolo with this simple floating-point [5x5] matrix multiplication. This code is copied from the TI benchmark sample and modified for [5x5] matrix size.
The code apparently runs for 100 iterations, but freezes at 1000 iterations and over. I would like to perform 100,000 loops.
#include <stdio.h>
#include <math.h>
void main(void) {
int j, m, n, p;
float m3[5][5] = { {0.0 , 0.0 , 0.0 , 0.0 , 0.0},{0.0 , 0.0 , 0.0 , 0.0 , 0.0},{0.0 , 0.0 , 0.0 , 0.0 , 0.0},{0.0 , 0.0 , 0.0 , 0.0 , 0.0},{0.0 , 0.0 , 0.0 , 0.0 , 0.0} };
const float m1[5][5] = { {0.0001, 0.001, 0.01, 0.1, 1},{0.001, 0.01, 0.1, 1, 10},{0.01, 0.1, 1, 10, 100},{0.1, 1.0, 10, 100, 1000},{1, 10, 100, 1000, 10000} };
const float m2[5][5] = { {0.0001, 0.001, 0.01, 0.1, 1},{0.001, 0.01, 0.1, 1, 10},{0.01, 0.1, 1, 10, 100},{0.1, 1.0, 10, 100, 1000},{1, 10, 100, 1000, 10000} };
printf("Benchmark Program \n");
printf("Starting \n");
for(j = 0; j < 100000; j++) {
for(m = 0; m < 5; m++) {
for(p = 0; p < 5; p++) {
m3[m][p] = 0;
for(n = 0; n < 5; n++) {
m3[m][p] += m1[m][n] * m2[n][p];
}
}
}
}
printf("Ending \n");
}
Screenshot attached. Any comments?