Hi Team,
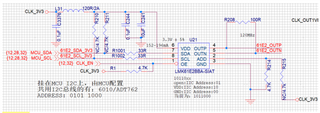
Customer is using our LMK61E2BBA-SIAR in their design, but facing high failure for no clock output issue now after some times running for their machine. We verified the failure IC on our EVM, and it shows the same behavior without any clock output. Below we captured the output waveform and registers dump compared with good units, please help to check what's the problem in here. Please help to check as your earlier as possiable, as this issue is blocking customer's mass production now. Thanks.
Good unit output clock waveform and register dump:
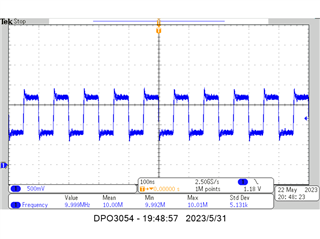
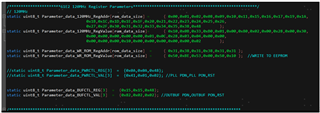
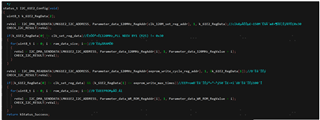
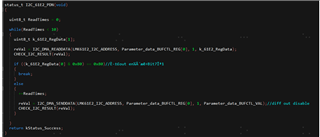
R0 0x0010 R1 0x010B R2 0x0233 R8 0x08B4 R9 0x0900 R16 0x1000 R17 0x1180 R21 0x1502 R22 0x1600 R23 0x172E R25 0x1900 R26 0x1A2E R27 0x1B00 R28 0x1C00 R29 0x1D00 R30 0x1E00 R31 0x1F00 R32 0x2001 R33 0x210C R34 0x2228 R35 0x2303 R36 0x2404 R37 0x2500 R38 0x2600 R39 0x2700 R47 0x2F28 R48 0x3003 R49 0x3110 R50 0x3228 R51 0x3300 R52 0x3405 R53 0x35FF R56 0x3800 R72 0x4800
Bad unit output waveform and registers dump:

R0 0x0010 R1 0x010B R2 0x0233 R8 0x0804 R9 0x0900 R16 0x1000 R17 0x1180 R21 0x1502 R22 0x1601 R23 0x17CC R25 0x1900 R26 0x1A2E R27 0x1B00 R28 0x1C00 R29 0x1D00 R30 0x1E00 R31 0x1F00 R32 0x2001 R33 0x210C R34 0x2228 R35 0x2303 R36 0x2404 R37 0x2500 R38 0x2600 R39 0x2700 R47 0x2F1D R48 0x3005 R49 0x3110 R50 0x321D R51 0x3300 R52 0x3400 R53 0x35FF R56 0x3800 R72 0x4800
Customer design files for your double check if any issues: