Part Number: DP83630
Other Parts Discussed in Thread: DP83640
Tool/software:
Hi,
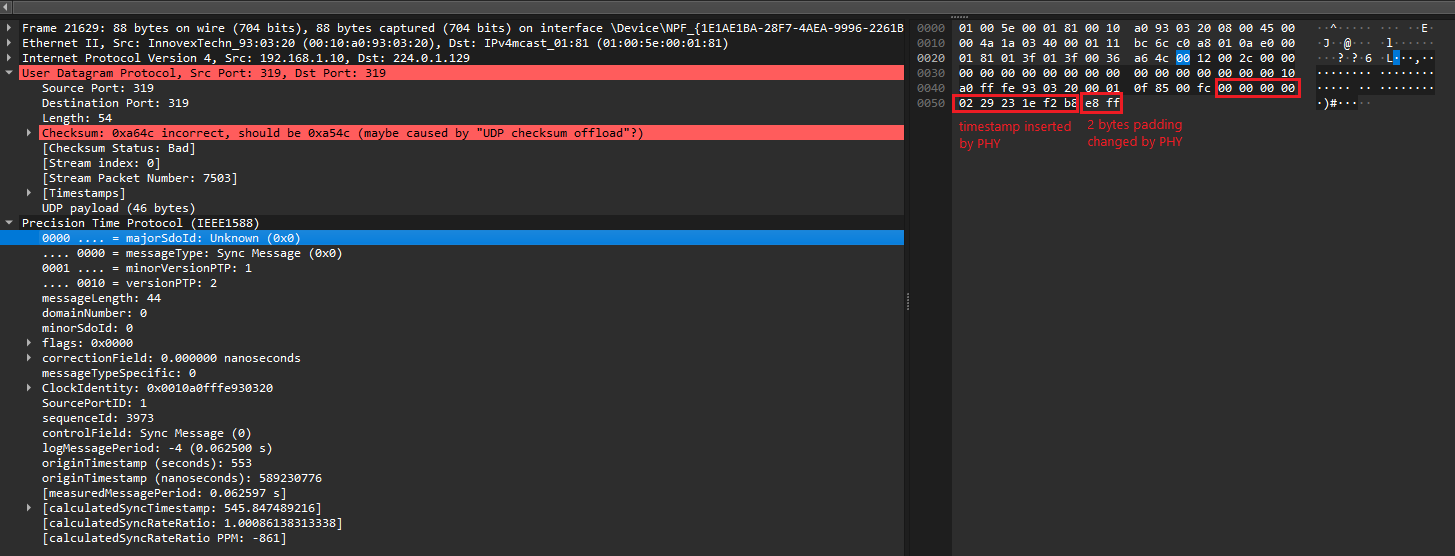
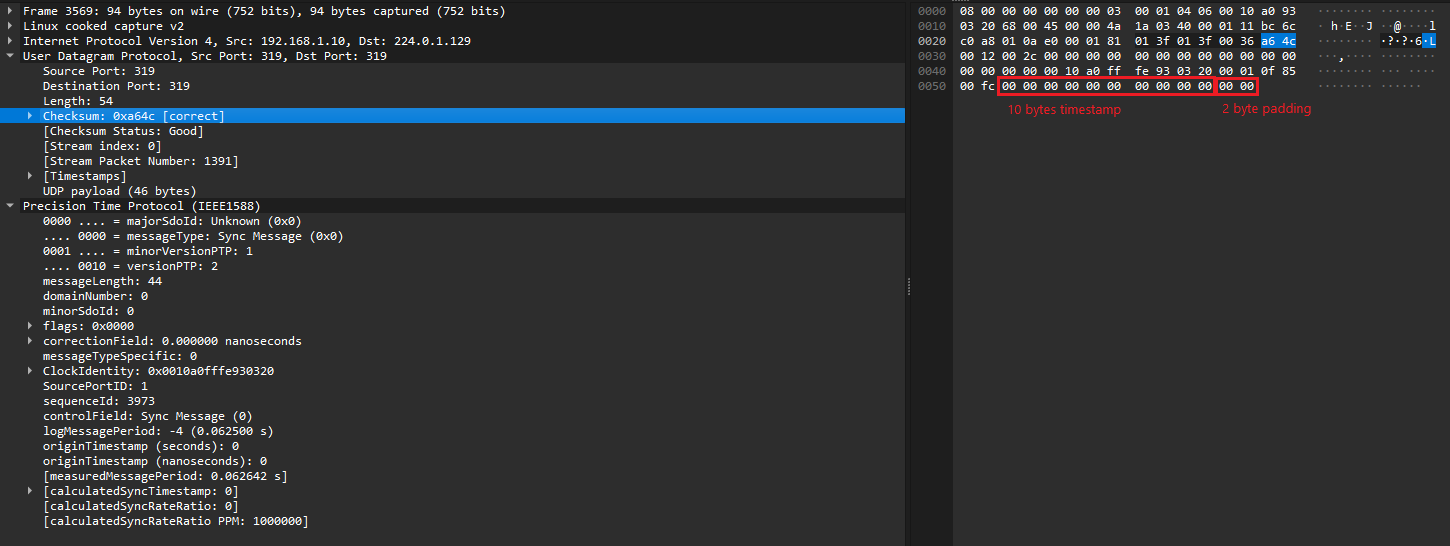
I am using DP83630 chip with Linux system for PTP. I have noticed that occasionally, once in a few hundreds of packets, in case of 1Step sync packets (where the DP83630 inserts correct timestamp and alternates the 2 paddings bytes in order to have correct checksum), the manipulated padding bytes causes the UDP checksum to still be wrong. The wrong UDP checksum is off by 1, for example 0x1538 instead of 0x1539.
Are you familiar with such behavior?
Just to note, I am using DP83630 EVK where the chip still has National Semiconductor logo.
Thanks,
Alexey.