Part Number: MCU-PLUS-SDK-AM243X
Other Parts Discussed in Thread: SYSCONFIG
Hi all,
I have two issues:
1. My M4 core will only launch sometimes
I haven't been able to find anything in my code to cause this, but if I build the exact same code 9/10 times it will load with no symbols. I can't open the ROV, see the stack, or anything. There's not much running on this core, but I've tried to increase the stack size of the tasks and no difference is made.
If I'm lucky, it will sometimes just work - no changes, I just need to keep trying and it will eventually load. I'm not sure what's changed to lead to this. Any help/suggestions are greatly appreciated.
2. sysconfig is really, really slow now
Is it normal for a multicore project using a lot of peripherals to be such a challenge for CCS 12?
It takes about 20 minutes now to just open a syscfg file from a project I'm working on. It's using most GPIO pins and other peripherals across all 5 cores, so it is comprehensive, but the time still seems disproportionate.
It also takes me about 20 minutes to run debug for the full multi core project, or 3 minutes for an individual core. This is very frustrating when I might forget to run the DSMC initialisation script between attempts, which means it's then 40 minutes.
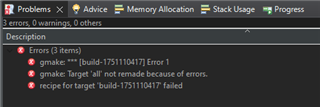
I know a part of the reason is that I do a full make clean before each build, which was the only way I could get a multicore project to actually build properly. But it seems to largely be the sysconfig portion.
Is there something I can do to speed things up? I'm using pretty powerful computers, so I'm surprised at how my dev has crawled to a snails pace with CCS.