Part Number: AM13E23019
Other Parts Discussed in Thread: MSPM0-DIAGNOSTIC-LIB,
hello, as a follow up from this topic
AM13E23019: ECC check exceptions - Arm-based microcontrollers forum - Arm-based microcontrollers - TI E2E support forums
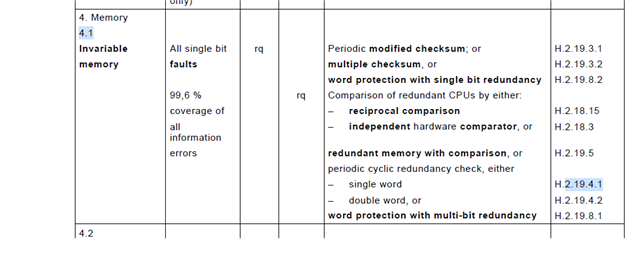
we are now interested how / to which safety standard the ECC implementation is compliant (with the known limitations). as the ecc behavior is the same for mspm0gxxx we are curious how this safety library ensures the complicance to IEC60730 as i would assume its part of the memory part of the diagnostic library from here.
MSPM0-DIAGNOSTIC-LIB Driver or library | TI.com
i requested access to it, to get more clarity on it.
BR