


Part Number: TM4C1294NCPDT
Other Parts Discussed in Thread: SYSBIOS
Tool/software: TI-RTOS
Hello all,
I'm using FPU in a SWI context (priority 15). When doing a comparison between 2 floats always expected to be equal sometime (about one over some million) I get comparison fail.
Placing a hw breakpoint shows that S0, and sometime also S1 report uncorrect value.
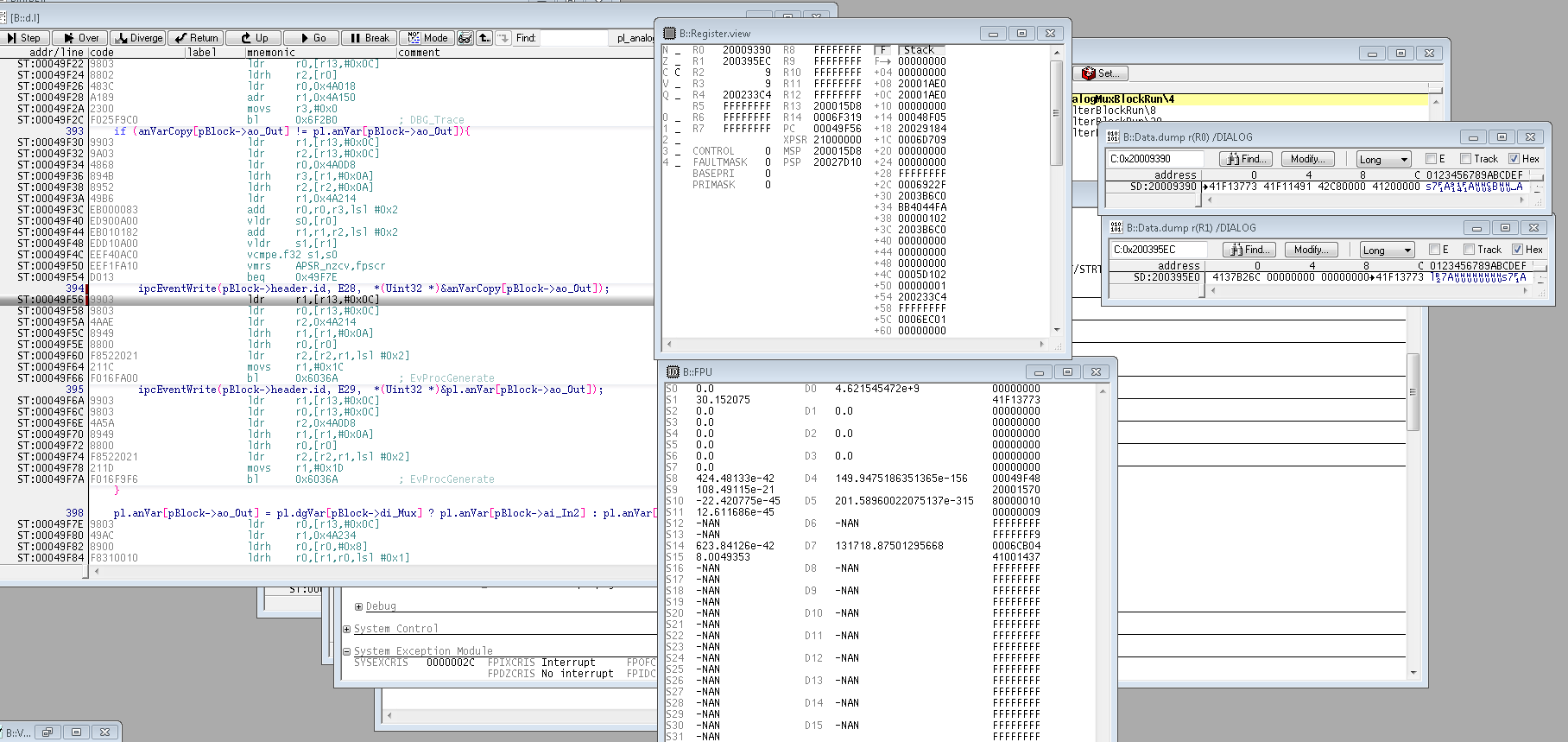
I've attached a screenshot where CPU is halted after comparison fails.
There S0 and S1 are loaded from addresses contained in R0 and R1, both locations contain the correct values, 30.152075 that is 0x41F13773. However, in S0 now I see 0 which is the reason breakpoint is hit.
By tracing flow with some homemade ram logger I see that problem occurs only if this SWI function is interrupted by a HWI, that I would consider not using floating point unit.
I'm using tirtos_tivac_2_14_00_10.
All I can think about is something that FPU regs are not saving at context switch and someone could use them.
Is there any way to tell OS to save them when preempting SWIs?
BR.
Lorenzo.


