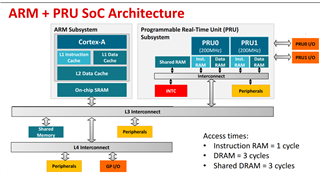
There's some explanation here
But I found some different instruction representations.
Sometimes LBBO takes 3 clock cycles to get the first 4 bytes of data from PRU internal memory, but sometimes it takes 4 clock cycles to do the same thing. That makes me supper confused.
I want to know what factors will affect the clock cycles took by LBBO?